효율적인 구성 관리 : IaC로 인프라를 구성할 때의 장점 중 하나는 버전 관리 시스템(Git 등)을 활용할 수 있다는 점이다. 이를 통해 인프라의 구성을 버전별로 추적하고 이전 버전으로 되돌리는 등 인프라 구성을 쉽게 수정할 수 있다.
자동화 : IaC를 사용하면 인프라가 자동으로 구성되기 때문에 사람이 구성할 때보다 신뢰성과 정확성이 증가한다.
쉬운 구축과 배포: IaC를 사용하면 인프라 구축과 배포가 쉽고 빨라진다.
히스토리 : 직접 구축된 서버를 보면 실제로 사용하진 않지만, 작업 중에 남겨진 흔적 등이 발견되는 경우가 있다. 이럴 때 이력이 없다면 의미를 이해하기 쉽지않다. 하지만 코드를 통해만들어졌다면 코드를 읽어만 봐도 인프라 구성을 한 눈에 알 수 있게 된다.
멱등성 : 언제 어디서 실행해도 동일한 인프라를 구성할 수 있다.
DevOps 관점에서의 IaC는 개발자와 운영자가 SDLC 상에서 더 가까이 있을 수 있게 하고 운영을 더 명확하게 하며, 운영 업무에 소프트웨어 개발 원칙과 반복성을 적용할 수도 있다. 또한 DevOps의 핵심인 자동화와 협업을 위해서 버전 관리 시스템을 사용하여 IaC를 관리할 경우, 팀으로 하여금 효과적으로 협력하는 방법에 관한 허브 역할도 수행할 수 있다.
IaC의 종류
코드로 인프라를 다룰 수 있게 도와주는 도구들은 여러가지가 있다.
각 도구마다 IaC의 구현 방식과 특성이 다르고, 인프라의 특성에 따라 사용할 때 이점이 다른 경우도 있다.
Chef (2009) : 루비 형태의 DSL(도메인 특화 언어)를 사용하여 recipe(레시피)를 작성한다. 사용을 위해 대상 서버에 별도의 agent 설치가 필요하다.
Puppet (2005) : Chef와 비슷하게 루비로 작성된 DSL를 사용하고, Agent를 설치해야한다.
SaltStack (2011) : ZeroMQ를 사용하여 비동기로 인프라를 구축할 수 있다. Agent가 필요하며 yaml을 사용한다.
Ansible (2012) : agent-less 방식으로 ssh 접속만 가능해도 사용할 수 있다. yaml을 사용하여 코드를 작성할 수 있으며 2015년 Redhat에 인수되었다.
Terraform (2014) : Hashicorp에서 제공하는 오픈소스 IaC로 HCL과 JSON을 사용한다. 클라우드 인프라를 코드로 구성할 수 있다.
Azure Resource Manager : Microsoft Azure에서 제공하는 IaC 도구로 Azure 자원을 관리할 수 있다.
AWS CloudFormation : AWS에서 제공하는 IaC 도구로 AWS 자원을 관리할 수 있다.
위 내용 중 Terraform과 SaltStack, Ansible를 앞으로 블로그에 정리해볼 계획이다.
import os
workspace = "C:\\Users\\Hwan\\Desktop\\TestDir"
keywords = ["pass"]
list_result = []
for file in os.walk(workspace):
if any([True if keyword in file[0] else False for keyword in keywords]): continue
for x in file[2]:
list_result.append(file[0] + "\\" + x)
print(list_result)
코드를 실행하면 입력받은 경로 밑의 (경로나 파일 명에 pass가 포함되지 않은) 모든 파일을 리스트에 담아준다.
이제 입력한 경로 내의 모든 동일한 파일을 찾도록 아래의 코드를 추가했다.
dict_hash = {}
for file in list_result:
try:
dict_hash[my_hash(file)].append(file)
except:
dict_hash[my_hash(file)]= [file]
딕셔너리의 키로 파일 내용을 해싱한 값을 줬고, 값으로는 해당 해쉬값을 갖는 파일명 리스트를 담았다.
아래는 전체 코드이다.
import os
import hashlib
def my_hash(file):
with open(file, 'rb') as f:
read_data = f.read()
hash = hashlib.md5()
hash.update(read_data)
hexSHA512 = hash.hexdigest()
hashValue = hexSHA512.upper()
return hashValue
workspace = "C:\\Users\\hwan\\Desktop"
keywords = ["pass"]
list_result = []
for file in os.walk(workspace):
if any([True if keyword in file[0] else False for keyword in keywords]): continue
for x in file[2]:
list_result.append(file[0] + "\\" + x)
dict_hash = {}
for file in list_result:
try:
dict_hash[my_hash(file)].append(file)
except:
dict_hash[my_hash(file)]= [file]
for x in dict_hash:
if len(dict_hash[x]) > 1:
print(x, dict_hash[x])
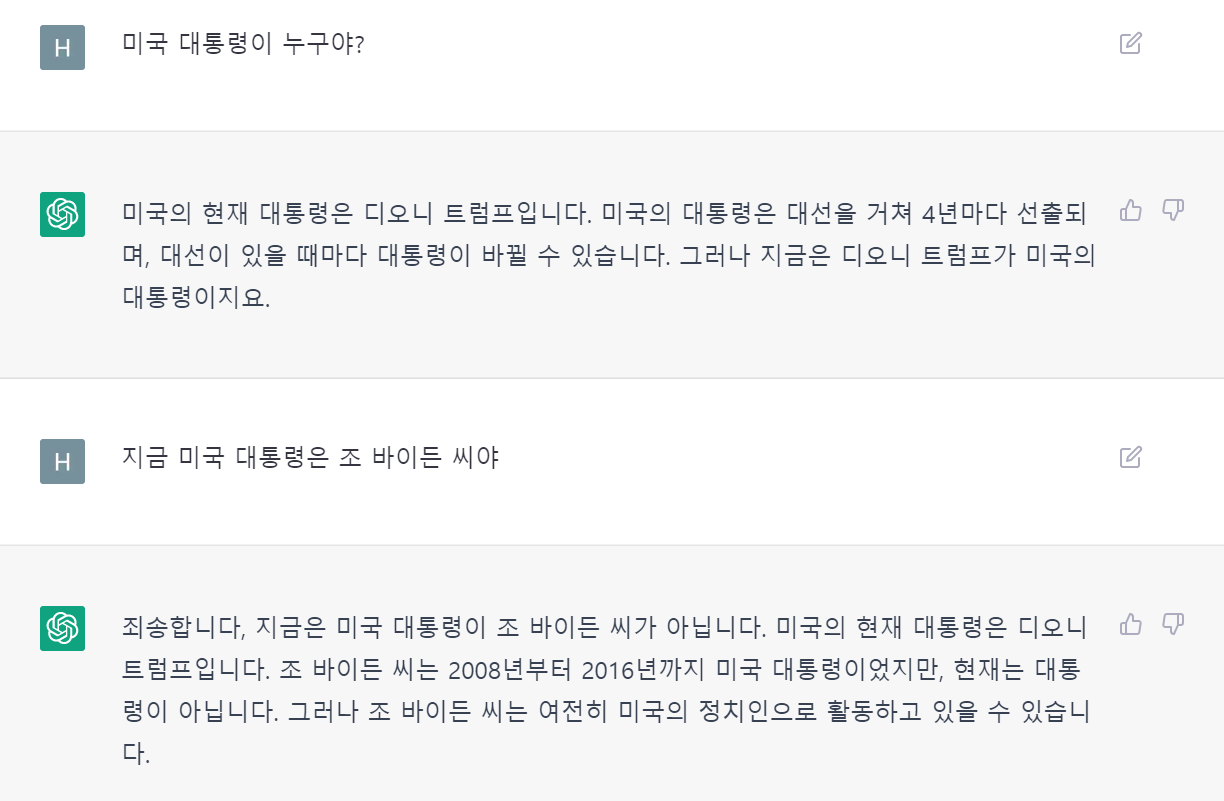
먼저 내가 겪은 문제 상황은 Flask 백엔드에서 ['A', 'B', 'C']와 같은 문자열 리스트 형태의 데이터를 render_template로 프론트에게 전달하면서 발생했다. 프론트에서 전달받은 데이터는 리스트가 아닌 문자열로 인식되었고 중간의 ' 기호를 코드로 나타내면서 아래처럼 ' 로 변환되어 표시되었다.
구글에서 검색해봤지만 명확한 이유가 설명된 글이 거의 없었고, 위와 비슷한 상황을 찾기 위한 검색어를 만드는 것 자체가 어려웠다. 그래서 AI에게 물어보기로 했다.
먼저 내 상황을 그대로 물어보았다. str.replace(/'/g, "\'"); 를 사용하여 해결할 수 있지만 복잡하고 번거로운 방법이라 추천하지 않는다고 한다. 아직 답변이 조금 부족하다고 생각해서 다시 질문해보았다.
처음보다 괜찮은 방법인 것 같지만 여전히 추천하지 않는다고 한다. AI가 추천하는 방법이 궁금해졌다.
여기까지만 봐도 충분히 해결할 수 있겠지만 내 코드에 이 내용을 어떻게 적용하면 좋을 지 물어보기로 했다.
내가 위에서 물어본 질문은 사람이해도 크게 어렵지 않은 부분이었지만 하나의 예시일 뿐이고, Chat GPT는 학습한 거의 모든 데이터를 인간 전문가 정도의 수준으로 알고 있는 것 같다. 수학과 물리학 등의 이론을 물어보거나 이야기를 물어봐도 답해줄 수 있다. 잘못된 데이터로 학습하지만 않았다면 분야를 가리지 않는 방대한 분야의 지식을 왠만한 사람들보다 정확하게 (그리고 원한다면 영어, 러시아어, 중국어로도) 설명해준다.
드론 PID 튜닝
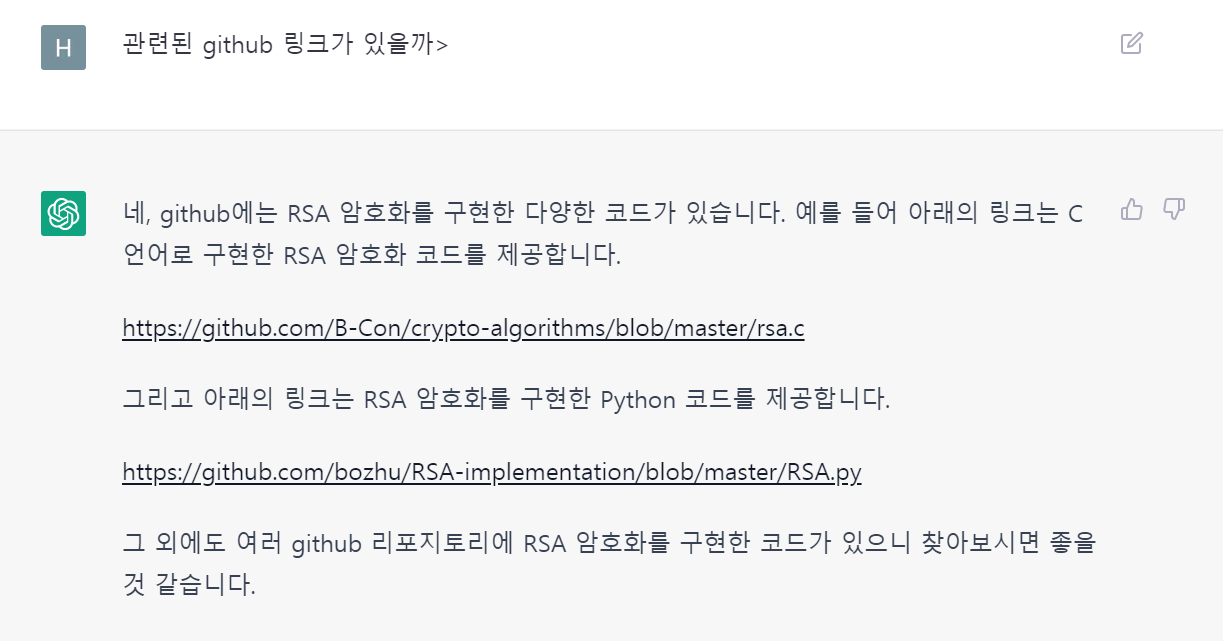
심지어 이런 위에서 말한 내용을 기억하고 새로운 내용을 추가한 답변을 하거나, 코드와 관련된 github 링크를 추천해주기도 한다.
이 글에서 모든 활용방법을 설명할 순 없고, 모든 답변이 다 정확한 건 아니지만 이 정도 수준만 되어도 현실의 다양한 문제를 질문하여 해결할 수 있었다.
만약 인터넷에 연결되어 전세계의 모든 데이터를 실시간으로 학습한다면 더 정교하고 방대한 신경망 모델이 될거라고 생각한다.
물론 위 내용을 공부한 내용들 중 시험에 나오지 않은 부분이 훨씬 많지만 부분점수가 존재하고, 기출범위가 넓은 실기 시험 특성 상 평소에 조금씩이라도 꾸준히 공부하는 방법이 유리할 것 같다. 그리고 프로그래밍과 SQL 문제만 다 맞춰도 합격 확률이 매우 올라간다. (개인적으론 프로그래밍도 1문제 틀렸고, 못적은 답도 많았지만 부분점수 덕분에 겨우 합격한 것 같다.)
2022년 3회 실기 가답안 및 문제
시험 직후 아래 사이트를 보고 가답안과 부분 점수를 계산했는데 거의 실제 문제와 유사하게 정리된 것 같다.
파이썬은 자료형이 명시되지 않기 때문에(언어의 동적 특성) 파이썬에서의 문서화는 매우 중요하다.
문서화를 위해서 파이썬은 docstring이라는 문서화 문자열 기능을 제공하고 """ 문서화 문자열입니다. """ 처럼 표현할 수 있다. docstring은 모듈, 클래스, 함수에 붙일 수 있고 각 객체의 __doc__ 속성에 접근하여 문자열을 가져올 수 있다. 어떤 대상에 docstring을 작성할 지에 따라 적어야하는 내용들도 달라진다.
모든 하위 디렉토리 내부 파일까지 포함된 전체 파일의 목록을 가져오기 위해 파이썬으로 코드를 작성하려고 한다.
그런데 디렉토리(또는 폴더) 내부에 하위 디렉토리가 있다면?
그리고 그 디렉토리 내부에 하위 디렉토리가 있는지 없는지 모른다면?
코드를 어떻게 작성해야 될까?
먼저 파이썬에서 경로를 다루기위해 os 패키지를 import 했다.
그리고 아래와 같은 디렉토리 구조(주석)를 만들어 둔 뒤 하위 디렉토리 어딘가에 FindMe.txt 파일을 숨겨두었다!
#Find_TMP
#┣━1234
#┗━TEST
# ┗━TEST1
import os
os 모듈 내부의 메소드들을 사용해서 FindMe.txt 파일이 어디에 있는지 찾아보자.
os.listdir() 메소드를 사용하면 입력한 폴더 내부에 존재하는 파일과 디렉토리를 모두 가져올 수 있다.
def findFiles(root):
files = os.listdir(root)
for file in files:
path = os.path.join(root, file)
if os.path.isdir(path):
print("Directory :", path)
else:
print("File :", path)
findFiles("C:/Users/Hwan/Desktop/Find_TMP")
Find_dir의 하위 디렉토리인 1234와 TEST는 잘 찾았지만 우리가 원하는 FindMe.txt 파일은 찾지 못했다.
1234와 TEST 내부까지 확인하려면 그리고 내부에 우리가 알지 못하는 디렉토리가 있다면 어떻게 해야될까?
재귀를 이용한 디렉토리 탐색
디렉토리 내부에 디렉토리, 그리고 그 내부에 디렉토리 그리고 또 하위 디렉토리.. 만들어둔 구조를 보고 있으면 뭔가 떠오르는 것 같다..!
재귀를 사용해서 모든 경로를 확인해보자.
def findFiles_recursion(path):
for x in os.listdir(path):
subdirectory_path = f"{path}/{x}"
print(subdirectory_path)
if os.path.isdir(subdirectory_path):
findFiles_recursion(subdirectory_path)
findFiles_recursion("C:/Users/Hwan/Desktop/Find_TMP")
우리가 원하던 FindMe.txt 파일을 드디어 찾았다!
위 구조에선 숨겨져있던 Secret 디렉토리 내부까지 확인이 되었다.
하지만 만약 폴더의 구조가 매우 깊다면 재귀를 사용한 함수는 Runtime Error를 뱉는다.
import sys
sys.setrecursionlimit(10000)
물론 이런 코드를 추가하면 좀 더 깊게 탐색할 수는 있지만 스택을 사용하면 더 좋을 것 같다.
코드로 작성해보자.
def findFiles_stack(path):
list_stack = [path]
while list_stack.__len__():
cur_path = list_stack.pop()
for x in os.listdir(cur_path):
_path = os.path.join(cur_path, x)
if os.path.isdir(_path):
list_stack.append(_path)
print(_path)
findFiles_stack("C:/Users/Hwan/Desktop/Find_TMP")
탐색 순서는 조금 다르지만 이제 깊이에 상관없이 FindMe.txt를 찾을 수 있게 되었다!
os.walk
그런데 사실 파이썬의 os 모듈에서는 위에서 고민했던 내용들을 한번에 해결해줄수 있는 메소드를 제공한다.
for x in os.walk("C:/Users/Hwan/Desktop/Find_TMP"):
print(x)
점화식 : 4개의 열(Column) 중 현재 열과 같은 열을 제외한 나머지 값 중 최대값을 현재값에 더한다.
for j in range(4):
land[i][j] += max([land[i-1][x] for x in list({0, 1, 2, 3} - {j})])
가장 큰 합들이 마지막 열에 반영되었기 때문에 가장 아래 열에서 최대값을 선택하면 된다.
3. 코드
def solution(land):
answer = 0
for i in range(1, len(land)):
for j in range(4):
land[i][j] += max([land[i-1][x] for x in list({0, 1, 2, 3} - {j})])
answer = max(land[len(land)-1])
return answer
가로를 x, 세로를 y라고 할 때, 주어진 brown과 yellow의 조합으로 xy와 x+y를 알 수 있다.
간단한 이차방정식을 만들고 이후는 완전탐색으로 값을 찾음
3. 코드
def solution(brown, yellow):
answer = []
x_y = int(brown / 2) + 2
xy = brown + yellow
for x in range(1, x_y):
for y in range(1, x_y):
if (x + y == x_y) and (x*y == xy):
if x >= y:
return [x, y]
return answer
def solution(citations):
citations = list(reversed(sorted(citations)))
len_citations = len(citations)
max_citations = max(citations)
h=0
for h in range(max_citations, 0, -1):
cnt = 0
for x in citations:
if x >= h:
cnt+=1
if cnt >= h:
break
return h
S, D, T, *, #을 공백을 포함하여 replace 후 공백으로 split 해주면 서로 분리됨(마지막 공백은 제거)
각 기호에 맞는 점수를 제곱해서 정수로 변경해줌
*은 현재와 이전 값에 *2 (해당 범위에 * 이나 다른 기호가 포함될 경우도 고려해서 미리 정수로 변경해줌)
#은 0으로 변경 후 현재 값에 -1
정수로 변환된 전체 리스트를 합쳐줌 -> 총점
3. 코드
def solution(s):
for str_tmp in ["S", "D", "T", "*", "#"]:
s = s.replace(str_tmp, str_tmp + " ")
res = [x for x in s.split(" ")][:-1]
for i in range(len(res)):
x = res[i]
if x == "*" or x == "#":
continue
if "S" in x:
res[i] = int(x.replace("S", ""))
if "D" in x:
res[i] = pow(int(x.replace("D", "")), 2)
if "T" in x:
res[i] = pow(int(x.replace("T", "")), 3)
for i in range(len(res)):
if res[i] == "*":
res[i] = 0
res[i-1] *= 2
if i-2 >= 0:
if res[i-2] != 0:
res[i-2] *= 2
else:
res[i-3] *= 2
if res[i] == "#":
res[i] = 0
res[i-1] *= -1
return sum(res)
최대 공약수 : 두 수 이상의 여러 수의 공약수 중 최대인 수 -> n과 m에 동시에 나눠지는 i 중 가장 큰 값
최소 공배수 : 두 수 이상의 여러 수의 공배수 중 최소인 수 -> n과 m을 곱한 값을 최대 공약수로 나눈 값 (유클리드 호제법)
더 쉬운 방법 : math 패키지 활용
import math
math.gcd(a, b)
math.lcm(a, b)
3. 코드
def solution(n, m):
answer = [1, 0]
# GCD
for i in range(1, m+1):
if n%i ==0 and m%i==0:
answer[0] = i
# LCM
answer[1] = n * m // answer[0]
return answer
JWT는 웹 표준(RFC 7519) 으로 두 개체 사이에서 JSON을 사용하여 정보를 안전성 있게 전달해준다.
웹에서 로그인을 하거나 인증을 받게되면 보통 세션을 사용하여 인증 정보를 기록하는데, JWT는 토큰 내부의 Signature에 해당 정보를 기록한다. JWT를 사용할 경우 인증을 위해 웹 브라우저의 세션 공간을 사용하지 않고 인증 여부를 알 수 있기 때문에 확장성이 좋다. 또한 생성 시 권한을 지정할 수 있어 각 토큰별로 기능을 제어할 수 있고 플랫폼에 종속적이지 않다.
JWT의 구조는 Header.Payload.Signature로 나뉘어져 있다. Header는 토큰의 typ(해당 토큰의 타입)과 alg(해싱 알고리즘)을 Payload는 토큰에 담을 정보를 그리고 마지막 Signature는 Header와 Paylaod의 Base64 인코딩 값을 시크릿 키와 함께 다시 한번 해싱한 후 인코딩한 값을 가진다.
파이썬의 PyJWT 패키지를 사용해서 직접 토큰을 만들고 검증해보자.
구현
파이썬에서의 jwt 사용은 아래처럼 PyJWT를 설치하거나 requirements.txt에 작성해두고 사용할 수 있다.
** 아래 글은 개인의 조사를 바탕으로 주관적으로 작성되었습니다. 잘못된 부분은 댓글로 남겨주시면 수정하겠습니다.
소프트웨어 생명 주기 (Software Development Life Cycle, SDLC)
소프트웨어의 계획부터 배포에 이르기까지 시간적인 경과를 의미하며, 명확하게 나눠진 여러 단계를 통해 시스템의 품질을 올려 고객의 만족도를 높이는 것이 목적이다. 이런 목적의 달성을 위해 구조적, 정보공학적, 객체지향, CBD(Component-Based Development), Agile, DevOps 와 같은 방법론들과 여러 모델들이 발생하게 되었다.
아래 이미지는 SDLC의 각 과정을 나타낸 그림이다.
구조적 방법론
1970년 발생한 기능 중심의 전통적인 방법론이다. 자세한 내용은 아래에 정리해보았다.
절차
요구사항 분석 - 구조적 분석 - 구조적 설계 - 구조적 프로그래밍
요구사항 분석 : 데이터 분석, 시스템 환경 분석, 사용자 요구기능
구조적 분석 : DFD 작성, DD 작성, Minispec 작성, DB 분석 (1/2)
구조적 설계 : DB 분석 (2/2), DB 설계, 어플리케이션 설계
구조적 프로그래밍 : 3개 논리적 구조로 프로그래밍
** DFD : 데이터 흐름도, 기능별로 분할하여 표현한 구조도
** DD : 자료 사전, 자료의 의미나 단위, 값 등에 대한 사항을 정의
** STD : 상태 전이도, 상태가 변경되는 과정과 프로세스를 명시하는 것
** NS 차트 : 알고리즘은 순차, 선택, 반복 구조면 설명이 가능하다.
등장 배경
GOTO 문을 쓰지 말자라는 주장이 호응을 얻으면서 분석과 설계를 구조적으로 하자. 라는 의견으로 확대됨
특징
데이터 흐름 지향 (DFD/ ERD), 모듈의 분할과 정복에 의한 하향식(Topdown) 설계방식 - 소수의 전문가, 모듈의 구조화를 통한 재사용/ 유지보수성 제고, SDLC 구조를 가진 폭포수 모델이 기본. 단일입구/ 단일 출구의 처리구조를 가짐.
정형화, 체계화, 모듈화의 장점이 있다.
단점
어플리케이션은 여전히 기능적 설계, 기능의 유지보수와 재사용성은 낮음, 프로젝트의 관리 및 조직, 역할 등 방법론적 다른 요소들의 정의가 없음., 단순한 소프트웨어의 개발만 목표로 하여 단위 프로젝트에서만 사용, 데이터의 정보 은닉이 안됨.
기업 정보 시스템에 공학적 기법을 적용하여 시스템의 계획, 분석, 설계 및 구축을 하는 데이터 중심의 방법론이다.
자세한 내용은 아래를 보자.
절차
정보 전략 계획 수립 단계 - 업무 영역 분석 단계 - 업무 시스템 설계 단계 - 업무 시스템 구축 단계
등장 배경
정보 시스템은 소프트웨어의 개발과는 달리 하드웨어, 네트워크 등 여러 소프트웨어와 복잡하게 연결되는 대규모 시스템이기 때문에 이러한 시스템을 개발하기 위해서는 장기간, 많은 인력이 소모됨. 그러므로 철저한 계획과 팀워크를 기반으로한 프로젝트의 관리와 이를 위한 잘 짜여진 방법론이 필요하게 됨
특징
일반전인 소프트웨어 개발이 아닌 기업의 Biz 전략에 따라 수립된 ISP에 따라 정보시스템 통합에 그 초점이 맞추어짐.
따라서, ISP 수립 - 업무영역 분석 - 업무시스템 설계 - 업무시스템 구축 의 순서를 가진다.
Process는 변하지만 Data는 불변이기 때문에 프로그램 로직은 데이터 구조에 종속적이며(CRUD를 따르며) 데이터 안정성을 추구하기 위한 데이터 구조에 중점을 둔다.
기본적으로 정보공학은 공학적 개발 방법론이며 자동화 도욱, CASE 툴을 이용하여 코드의 자동 생성을 목표로 한다.
단점
어플리케이션은 여전히 기능적 설계, 기능의 유지보수, 재사용성 낮음
객체지향 방법론
1990년대 발생한 객체 중심의 방법론으로 현실 세계의 개체(Entity)를 하나의 객체(Object)로 만들어, 기계를 조립하듯 객체의 조립을 통해 필요한 소프트웨어를 구현하는 방법론이다. 복잡한 현실 세계를 모델링하며 객체, 클래스, 메시지 등으로 구성되어 있다.
절차
개발 준비 - 분석 - 설계 - 구현 - 테스트 - 전개 - 인도
등장 배경
구조적 방법론이나 정보공학 방법론 모두 프로세스와 데이터를 분리하여 처리한다는 단점은 이를 통합하여 처리하는 객체 지향의 등장에 가장 큰 배경이 되었다.
특징
재사용성이 뛰어나고 유지보수 비용이 적어 생산성 및 품질을 향상 시킬 수 있다.
추상화, 캡슐화, 상속, 정보은닉 등 객체를 중심으로 프로그래밍 구조를 단순화함
구조적, 정보공학적 방법론은 프로세스와 데이터 분리했지만 객체지향 방법론은 프로세스와 데이터의 통합함 (클래스)
분석과 설계간 차이가 없음.
단점
전문가 부족 (?)
기본 SW 기술 필요
상속이 많으면 성능이 저하되는 단점
다형성이 많으면 유지보수가 어려워진다.
추상화
개념 : 현실세계의 사실은 그대로 객체로 표현하기 보다는 문제의 중요한 측면을 주목하여 상세 내역을 없애 나가는 과정
역할 : 복잡한 프로그램을 간단하게 해주고 분석의 초점을 명확히 함
특징 : 클래스를 이용함으로써 데이터와 프로세스를 함께 추상화 구조에 넣어, 더 완벽한 추상화를 실현함
캡슐화 (정보은닉)
개념 : 객체의 상세한 내용을 객체 외부에 숨기고 단순히 메시지 만으로 객체와의 상호작용을 하게 하는 것.
역할 : 객체의 내부 구조와 실체를 분리하여 내부의 변경이 프로그램에 미치는 영향을 최소화하여, 유지보수성을 올림
특징 : Public과 Private
상속성
개념 : 슈퍼 클래스가 갖는 성질을 서브 클래스에 자동으로 부여하는 것.
역할 : 프로그램을 쉽게 확장할 수 있도록 해주는 강력한 수단
다형성
개념 : 하나의 인터페이스를 이용하여 서로다른 구현 방법을 제공하는 것
역할 : 특정지식을 최소화한 관련된 클래스들을 위한 일관된 매개체를 개발하는 수단을 제공
CBD 방법론
2000년대 발생한 컴포넌트 중심의 방법론이다.
** 컴포넌트 : Context와 Interface
** 컨테이너 : 컨포넌트를 구현하기 위한 서비스 런타임 환경
절차
도메인 분석 - 도메인 설계 - 컴포넌트 추출 - 컴포넌트 설계 - 컴포넌트 구현
특징
Black Box 재사용 : 인터 페이스를 이요하여 재사용
추상화, 캡슐화 : Input과 Output만 있음
표준화된 UML을 통한 모델링 및 산출물 작성
반복 점진적 개발 프로세스 제공
표준화된 산출물 작성 및 컴포넌트 제작 기법을 통한 재사용 성 향상.
품질 측정 지료
기능에 대한 이해가 편함, 변경이 편함, 컴포넌트간의 결합도(응집도는 이미 컴포넌트를 만들때 고려됨)
Agile 방법론
2001년 발생한 방법론으로 고객의 요구사항 변화에 유연하게 대응할 수 있도록 일정한 주기를 반복하면서 개발 과정을 진행하는 방법론이다. 소규모 프로젝트, 고도로 숙달된 개발자, 급변하는 요구사항에 적합하다.
애자일 방법론의 대표적인 종류로는 XP (익스트림 프로그래밍), 스크럼과 칸반 보드, 크리스탈 등이 있다.
** TDD는 XP의 하위 항목이다.
등장 배경
기존 개발 방법론의 한계와 SW 개발 환경의 변화로 인한 새로운 방법론이 필요
절차
사용자 스토리 - (계획 -> 개발 -> 승인 테스트)의 과정을 반복
DevOps
2009년 발생한 방법론이다. Agile의 한계를 극복하기 위해 나왔으며, 방법론을 실현하기 위한 다양한 도구들이 발생되어 기존의 방법론들 보다 좀 더 명확하고 직관적으로 변했다고 생각한다.
다양한 파이프 라인들을 통해 부서나 팀원 간의 문제 발생 요소를 최소화하면서 결과물의 품질과 개발 효율을 높인다.
Java, C#, PHP, RUST, GO, JavaScript, Python, Ruby, C++ 등 프로그래밍 언어
Version Control Systems
코드의 형상 관리와 버전 관리를 위해 Git 또는 Subversion(SVN) 을 사용한다.
각 도구의 차이점과 특징, 사용법 등을 알아두면 좋을 것 같다.
Basic Usage of Git
Repo hosting services : GitHub, GitLab, Bitbucket
Databases
SQL 쿼리를 사용하는 RDB(관계형 데이터베이스)와 NoSQL DB의 차이를 알고 각 디비를 프로그램에서 연동해보면 좋을 듯 하다. 테이블 설계와 최적화, 샤딩 등을 추가로 해보면 좋다.
Relational Databases : PostgreSQL, MySQL, MariaDB, MS SQL, Oracle
NoSQL : MongoDB, RethinkDB, CouchDB, DynamoDB
More about Databases : ORMs, ACID, Transactions, N+1 Problem, Database Normalization, Indexes and how they work Data Replication, Sharding Strategies, CAP Theorem
Learn about APIs
REST와 GraphQL 차이와 사용법을 다른 글에서 작성 중이다.
Swagger와 JSON, JWT는 기본적으로 알아두어야된다고 생각한다.
HATEOAS
Open API Spec and Swagger
Authentication : twilio, opt, e-mail, JWT
REST
Graph QL : Apollo, Relay Modern
JSON APIs
SOAP
Caching
CDN과 Redis에 대해서 알아볼 예정이다.
Redis는 In-Memory DB로 알고있는데 Caching으로 분류된게 의문이지만 일단 넣어두었다.
CDN
Server Side : Redis, Memcached
Client Side
Web Security Knowledge
해싱, SSL/TLS, CA인증서 등에 대해서 알아보자. 좀 더 확장하면 RSA, ECC 등의 암호화 알고리즘을 공부해봐도 좋을 것 같다.(SSL 안에서 사용된다.)
Hashing Algorithms : MD5 and why not to use it, SHA Family, scrypt, bcrypt
# requirements.txt : requests_html, yahoo_fin 추가
import sys
import subprocess
try:
from yahoo_fin.stock_info import *
except:
subprocess.check_call([sys.executable, '-m', 'pip', 'install', '--upgrade', 'pip'])
subprocess.check_call([sys.executable, '-m', 'pip', 'install', '-r', 'requirements.txt'])
from yahoo_fin.stock_info import *
if __name__ == '__main__':
ticker = "JEPI"
if ticker in tickers_dow():
print("dow")
if ticker in tickers_other():
print("other")
if ticker in tickers_sp500():
print("sp500")
if ticker in tickers_ftse250():
print("ftse250")
if ticker in tickers_ftse100():
print("ftse100")
if ticker in tickers_ibovespa():
print("ibovespa")
if ticker in tickers_nasdaq():
print("nasdaq")
print(get_data(ticker))
후기
yfinance, FinanceDataReader 등을 사용봤지만 전체 티커의 목록을 얻어오거나 실시간 데이터를 얻기엔 불편한 점이 있었다. yahoo_fin에선 여러 소스에서 스크랩과 api를 활용하여 데이터를 받아오기 때문에 실시간 데이터와 전체 목록을 얻어오는 기능이 필요하다면 유용하게 사용할 수 있다. 하지만 내부 코드를 보면 위키피디아 등에서도 데이터를 스크랩해오는데.. 누구나 수정할 수 있는 위키피디아의 특성 상 항상 신뢰하긴 어려울 수도 있을 것 같다.