검색을 통해 /etc/resolv.conf 등 필요한 파일들을 수정해줬고, DNS (8.8.8.8) 주소도 잘 설정되어 있다.
하지만 여전히 update가 안되었기 때문에 결국 필요한 패키지들을 수동으로 설치하기로 했다.
apt-get download
보통 필요한 패키지들은 apt-get install로 시스템에 바로 설치하지만 현재는 원인을 알 수 없는 이유로 저장소 연결이 제한된다. 패키지의 수동 설치를 위해서 먼저 docker 컨테이너를 빠져나가 apt-get이 잘 작동되는 os에서 필요한 패키지들을 다운로드 받는다.
$ sudo apt-get download vim net-tools iproute2 iputil-ping
apt-get download 명령어는 현재 디렉토리에 .deb 형태로 필요한 패키지를 다운로드 받는다.
aaa라는 임시 폴더를 만들어 내부에 필요한 deb 들을 설치했다.
이제 이 파일들을 도커 내부의 ubuntu:20.04로 전달하여 수동으로 설치하면 된다.
docker cp
도커는 도커 외부와 내부 컨테이너 간의 파일 공유가 가능하며 docker cp 명령어로 해당 기능을 제공한다.
위에서 내려받은 deb 파일을 ubuntu:20.04 컨테이너에 넣어준다.
$ sudo docker cp ../aaa/ test:/aaa/
잘 전달되었다.
이제 전달된 deb를 설치해주자.
apt install ./
apt install 명령어를 사용하면 패키지를 설치할 수 있다.
여기서 주의할 점이 있는데, install 뒤에 패키지 명을 그냥 입력하면 저장소에서 해당 패키지를 찾기 때문에
이 글에선 컨테이너 외부의 우분투에 미리 설정되어 있기 때문에 해당 파일을 도커 내부 같은 경로에 cp 명령어로 덮어씌워 줬다.
아래는 /etc/apt/source.list의 내용이고 기존 파일에 kakao 서버 주소만 추가해 주었다.
필요하다면 그대로 사용해도 좋고 다른 국내 서버 주소를 찾아서 추가해줘도 좋다.
$ vi /etc/apt/source.list
# deb cdrom:[Ubuntu 20.04.4 LTS _Focal Fossa_ - Release amd64 (20220223)]/ focal main restricted
# See http://help.ubuntu.com/community/UpgradeNotes for how to upgrade to
# newer versions of the distribution.
deb http://kr.archive.ubuntu.com/ubuntu/ focal main restricted
# deb-src http://kr.archive.ubuntu.com/ubuntu/ focal main restricted
## Major bug fix updates produced after the final release of the
## distribution.
deb http://kr.archive.ubuntu.com/ubuntu/ focal-updates main restricted
# deb-src http://kr.archive.ubuntu.com/ubuntu/ focal-updates main restricted
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team. Also, please note that software in universe WILL NOT receive any
## review or updates from the Ubuntu security team.
deb http://kr.archive.ubuntu.com/ubuntu/ focal universe
# deb-src http://kr.archive.ubuntu.com/ubuntu/ focal universe
deb http://kr.archive.ubuntu.com/ubuntu/ focal-updates universe
# deb-src http://kr.archive.ubuntu.com/ubuntu/ focal-updates universe
## N.B. software from this repository is ENTIRELY UNSUPPORTED by the Ubuntu
## team, and may not be under a free licence. Please satisfy yourself as to
## your rights to use the software. Also, please note that software in
## multiverse WILL NOT receive any review or updates from the Ubuntu
## security team.
deb http://kr.archive.ubuntu.com/ubuntu/ focal multiverse
# deb-src http://kr.archive.ubuntu.com/ubuntu/ focal multiverse
deb http://kr.archive.ubuntu.com/ubuntu/ focal-updates multiverse
# deb-src http://kr.archive.ubuntu.com/ubuntu/ focal-updates multiverse
## N.B. software from this repository may not have been tested as
## extensively as that contained in the main release, although it includes
## newer versions of some applications which may provide useful features.
## Also, please note that software in backports WILL NOT receive any review
## or updates from the Ubuntu security team.
deb http://kr.archive.ubuntu.com/ubuntu/ focal-backports main restricted universe multiverse
# deb-src http://kr.archive.ubuntu.com/ubuntu/ focal-backports main restricted universe multiverse
## Uncomment the following two lines to add software from Canonical's
## 'partner' repository.
## This software is not part of Ubuntu, but is offered by Canonical and the
## respective vendors as a service to Ubuntu users.
# deb http://archive.canonical.com/ubuntu focal partner
# deb-src http://archive.canonical.com/ubuntu focal partner
deb http://security.ubuntu.com/ubuntu focal-security main restricted
# deb-src http://security.ubuntu.com/ubuntu focal-security main restricted
deb http://security.ubuntu.com/ubuntu focal-security universe
# deb-src http://security.ubuntu.com/ubuntu focal-security universe
deb http://security.ubuntu.com/ubuntu focal-security multiverse
# deb-src http://security.ubuntu.com/ubuntu focal-security multiverse
# This system was installed using small removable media
# (e.g. netinst, live or single CD). The matching "deb cdrom"
# entries were disabled at the end of the installation process.
# For information about how to configure apt package sources,
# see the sources.list(5) manual.
# kakao
deb http://ftp.daumkakao.com/ubuntu/ bionic main restricted
deb http://ftp.daumkakao.com/ubuntu/ bionic-updates main restricted
deb http://ftp.daumkakao.com/ubuntu/ bionic universe
deb http://ftp.daumkakao.com/ubuntu/ bionic-updates universe
deb http://ftp.daumkakao.com/ubuntu/ bionic multiverse
deb http://ftp.daumkakao.com/ubuntu/ bionic-updates multiverse
deb http://ftp.daumkakao.com/ubuntu/ bionic-backorts main restricted universe multiverse
파일을 덮어씌우고 update와 upgrade를 한번씩 더 해줬다.
이제 python3, pip3, vim, venv를 apt-get install로 설치한다.
$ apt-get install -y python3 python3-pip python3-venv vim
Django가 설치된 환경은 Ubuntu 20.04 LTS 이다. python과 pip등 개발에 필요한 도구들을 설치해준다.
$ sudo apt-get install python3 pip3 venv vim
설치 후엔 좀 더 편하게 도구들을 사용하기 위해 .bashrc에 alias를 등록해준다.
각 사용자 계정에 위치한 .bashrc 파일을 열어 ll, la 등의 기본 alias 내용이 있는 곳에 같이 입력해주면 된다.
이 과정은 필수는 아니지만 개인적으로 해두면 편해서 만들어 줬다.
alias python='python3'
alias pip='pip3'
alias vi='vim'
입력 후엔 source .bashrc 명령어를 입력해준다.
$ source .bashrc
Venv 가상환경에 Django 패키지 설치하기
개발을 시작하기 전에 위에서 같이 설치해준 venv를 사용해서 파이썬 가상환경을 만들어준다.
가상환경을 만들면 프로젝트 단위로 패키지에 대한 관리가 자유롭다.
$ python -m venv test
test 라는 이름의 가상환경을 사용자 계정의 기본 경로 (/home/username/)에 만들어 줬다.
환경이 만들어지면 이미지처럼 기본적인 구조가 자동을 만들어진다.
하지만 아직 가상환경의 내부로 들어온 건 아니기 때문에 아래 명령어를 추가로 입력해 줘야 한다.
$ source bin/activate
bin 폴더 내부의 activate 스크립트를 실행하면 가상환경에 진입한다.
이제부터 pip로 원하는 패키지를 설치하면 해당 환경 내에서만 설치가된다.
django 설치가 완료되면 bin 폴더에 django-admin이 설치된걸 볼 수 있다.
$ pip install django
Django 프로젝트 생성 후 서버 실행
pip를 사용해서 장고를 설치하면 Django-admin이라는 툴이 같이 설치된 걸 볼 수 있다.
이 툴을 사용해 Django 프로젝트를 생성한다.
$ django-admin startproject project_name
projcet_name이라는 이름의 프로젝트가 잘 생성되었다.
웹서버를 실행해보자.
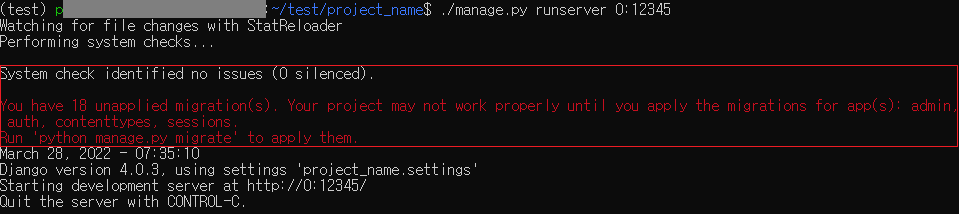
$ ./manage.py runserver 0:12345
빨간색 박스 부분에 migrate 경고가 뜬걸 볼 수 있는데, 실행은 되었기 때문에 다른 PC의 브라우저로 접속해보았다.
참고로 현재 서버는 다른 PC와 같은 공유기 밑에서 같은 c클래스 사설 아이피를 사용한다.
서버의 아이피와 포트를 입력해서 접속했지만 ALLOWED_HOSTS에 서버 IP를 추가하라는 경고 문구만 나온다.
위에서 만들어진 project_name/project_name 디렉토리 내부의 settings.py를 열어보면 아래 이미지와 같은 부분이 있다. ALLOWED_HOST =[] 에서 []사이에 서버 접속 시 사용할 주소를 'xxx.xxx.xxx.xxx' 형태로 넣어주면 된다.
Socket 으로 웹 페이지를 크롤링하는 HTTP 클라이언트를 직접 구현해야 한다면, 어떻게 하시겠습니까?
데이터 베이스
noSQL 과 RDB 의 특징, 차이에 대해 말씀해주세요. 어느 상황에 어떤 데이터베이스를 쓰는게 좋겠습니까?
데이터베이스가 자료를 빠르게 검색하기 위해 어떤 일을 할까요? 최대한 상세하게 설명해주세요.
RDBMS 의 여러 JOIN 중 아무거나 하나 골라서, 그림으로 설명해 주실 수 있습니까?
데이터베이스 샤딩 / 파티셔닝에 대해 설명해주세요.
데이터베이스가 Index 를 이용해 자료를 빠르게 검색하는 과정을, 우리 할머니도 알아들을 수 있도록 설명해 주시겠어요?
Stored procedure 를 이용한 시스템을 어떻게 유지보수 할 수 있습니까? Stored procedure 의 장점과 단점에 대해 말씀해 주세요.
Optimistic Locking(낙관적 락) 과 Pessimistic Locking(비관적 락) 에 대해 설명해주세요. 각각의 락을 사용할 상황 또는 제품 사례를 말씀해주세요.
어떤 서비스의 이용자 테이블이 있다고 가정합시다. 이용자 id 를 여러 테이블에서 FK 로 참조하고 있습니다. 그런데 이용자 테이블에 환경설정, 개인정보 등 정보를 한데 저장하다보니 Column 이 40개가 넘게 있는 상태입니다. 문제를 진단해 주시고, 해결 방안도 제시해 주시기 바랍니다.
Slow query 를 발견하고, 수정한 경험에 대해 말씀해 주세요.
저희는 도축장에서 전달받은 원육을 소매점에 도매하는 서비스를 운영하고 있습니다. 여기서, 원육과 소매점을 어떻게 테이블로 모델링 하시겠습니까?
어플리케이션의 문자열(String) 을 데이터베이스에 저장하기 위해 고려해야 할 사항에는 어떤 점이 있을까요?
Big data 를 다루려면 RDBMS 보다 NoSQL 이 더 좋다는 말이 많습니다. 그렇다면 large data set 에는 항상 NoSQL 만 써야 할까요? 반드시 RDBMS 만을 이용해 large data set 을 다루려면 어떻게 해야 할까요?
실 서비스의 데이터를 조작하고, 또 조회해야 하는 Admin app 을 만들어야 한다면, 어떻게 구현하시겠습니까?
데이터 마이그레이션 기간 동안 서비스 순단을 최소한으로 하고 싶습니다. 이런 요구사항에 맞는 테이블을 어떻게 설계하시겠습니까?
(JPA 경험자 한정) JPA 를 이용할 때, JPQL 을 쓰는 경우가 종종 있는데, JPQL 을 쓰시며 좋았던 점과 불편했던 점을 말씀해 주세요.
(JPA 경험자 한정) JPA 의 @Entity 란 뭔가요? 도메인 객체와 Entity 객체를 각각 어떻게 정의하시겠습니까?
(JVM 경험자 한정) 배열과 ArrayList, LinkedList 의 차이점은 무엇인가요?
자료 구조 및 알고리즘
지금 사용하시는 스마트폰의 화면을 캡쳐하는 프로그램을 만들어야 한다면 어떻게 하시겠습니까?
전화번호와 같은 민감한 정보를 어떻게 저장하는게 좋을까요? 관리자조차 모르게 저장하고 싶다면?
암호화란 무엇일까요? 알고 계신 암호화 방식 아무거나 하나만 설명해주세요.
어떤 알고리즘을 도입하기 전에, 성능을 판별해 보고자 합니다. 어떤 방법을 활용해, 어떤 기준으로 알고리즘의 효율을 판단하시겠습니까?
공개 키 암호화와 비밀 키 암호화에 대해 설명해주세요.
캡슐화에 대해 설명해주세요.
캐시란 뭐고, 어떤 목적으로 쓰는 건가요?
List 와 Set 의 차이에 대해 설명해주세요.
이진 탐색의 최선 / 최악의 경우에 대해 말씀해주세요.
손실 압축과 무손실 압축의 차이에 대해 설명해주세요.
RSA 로 공개 키를 만들 때, 키 길이를 정하는 기준이 있습니까? 키 길이를 길게 하면 암호화 문제를 완벽 해결할 수 있나요?
순환 Queue 를 만드려면 어떻게 하시겠습니까? 그리고 어떤 Queue 또는 Graph 가 무한 순환 구조라는 것을 어떻게 판단하시겠습니까?
압축 알고리즘을 설계하라는 요구사항이 들어왔다면, 어떻게 구현하시겠습니까?
전화번호부 앱을 만든다고 가정하겠습니다. 1명당 1KiB의 정보를 갖도록 모델을 설계했습니다. 앱이 온전히 사용할 수 있는 메모리가 4메가인 기기에서, 10000명(총 10메가)의 이용자 정보를 검색할 수 있도록 구현해야 합니다. 어떻게 하시겠습니까?
(JVM 경험자 한정) 배열과 ArrayList, LinkedList 의 차이점은 무엇인가요?
디자인 및 테스트
Singleton pattern 이란 무엇이고, 어떤 장점과 단점이 있을까요?
싱글턴 코드는 테스트를 어렵게 만드는 문제가 있습니다. 왜 그럴까요? 싱글턴이 좋지 않다는데 왜 스프링 프레임워크 같은 녀석들은 별다른 규칙이 없을 때 기본으로 Singleton bean 을 만들까요?
좋은 Test 라고 평가할 수 있는 가장 중요한 요소를 말씀해주세요. 후보자님은 어떤 Test 를 좋은 Test 라고 정의하십니까?
Callback function(또는 Closure) 이 뭔가요? 주의할 점이 있을까요?
Mutable, Immutable 이란 뭔가요? 각각은 어떤 특징이 있을까요?
Acceptance, Smoke, End-to-End, Integration, Unit test 같은 용어들을 본인만의 방법으로 구분짓는 기준이 있습니까?
메소드의 파라미터로 전달한 객체를 메소드 내에서 마음대로 바꾸지 못 하게 하려면 어떻게 코딩하는게 좋을까요?
왜 메소드가 파라미터를 조작하는 것이 문제가 될까요? 문제가 아닐 수도 있지 않을까요?
음료수 자판기에 탑재한 소프트웨어를 제작했다고 가정해 보겠습니다. 작성하신 소프트웨어의 통합 테스트 시나리오를 어떻게 작성하시겠습니까? 생각나는대로 말씀해 주세요.
현재 다루시는 플랫폼에서의 테스트 자동화를 어떻게 구축 하시겠습니까?
test code 를 작성하는 본인만의 기준이 있습니까? test 실행 속도를 높이려면 어떤 방법이 좋을까요?
blackbox testing, whitebox testing 의 차이에 대해 설명해주세요. 어떤 상황에서 어떤 테스트 방법을 사용하시겠습니까?
상속의 이점 중 "코드의 중복을 줄여준다" 는 말이 있습니다. 그런데 코드 중복을 줄이기 위해서 상속을 쓰는 것은 매우 좋지 않은 코딩 방식이라고 저희는 생각합니다. 이에 대한 후보자님의 의견을 듣고 싶습니다.
Java 의 Marker interface (아무 메소드도 없이 타입만 있는) 에 대해 어떻게 생각하시나요?
코드 응집성(cohesion)이란 말을 어떻게 설명하실 수 있습니까? 응집도가 낮은 코드와 높은 코드를 예를 들어 설명해 주세요.
NodeJS 로 실행하는 서버와 통신하는 Spring 또는 Python 서버를 구현할 때, 어떻게 하시겠습니까? HTTP 외의 방법을 쓰고 싶다면 어떻게 해야 할까요?
네이버 같은 서비스에서 IP 주소가 바뀔 경우 접속 경고 등의 오류를 발생시킨다. 어떻게 구현하시겠습니까?
서비스의 memory leak 을 어떻게 판단하고, 해결하시겠습니까?
우리 서비스가 대 성공해서 이용자가 4000만이 되었다고 가정합니다. 이용자 4천만 돌파 기념으로 선착순으로 접속한 사용자에게 보너스 포인트를 주는 이벤트를 운영하려 합니다. 모든 이용자들에게 공평하게, 플랫폼이 제공하는 Push 를 보내려 하는데요. 이 경우, 어떤 점들을 고려해야 할까요?
MSA vs Monolithic 을 선택하는 기준이 있습니까?
M 인프라 시스템이 A 시스템 대비 가격이 많이 싸졌다고 가정해 보겠습니다. 우리의 인프라 시스템을 A 에서 M 으로 최대한 빨리 바꾸려면 어떤 점을 고려해야 할까요?
우리 앱의 어떤 페이지(또는 특정 view) 의 로딩이 매우 늦다면 어떻게 개선할 수 있을까요?
우리가 사용하는 앱들의 API 는 예고없이 바뀌기도 합니다. 외부 API 가 마구 변경되는 상황에서도 우리 앱이 크래시 나지 않게 하려면 어떻게 해야 할까요?
제작한 애플리케이션이 얼마나 사용자 친화적인지를 측정할 수 있는 방법이 있을까요?
Java / JVM
JVM 에서의 autoboxing 이란 어떤 현상을 말하는 걸까요?
interface default implementation 이란? abstract class 를 상속받는 것과 기본 구현을 들고 있는 interface 를 implements 하는것은 어떤 차이가 있나요?
Java stream method 중 map 과 flatMap 의 차이에 대해 설명해주세요.
메소드에서 리스트 타입의 파라미터를 받을 때, ArrayList - List - Collection - Iterable 처럼 구체 타입 뿐 아니라 상위 타입도 받을 수 있습니다. 컬렉션을 받는 어떤 API 를 구현하실 때 구체 타입의 API 디자인을 선호하는지, 추상 타입의 API 디자인을 선호하는지를 설명해 주세요. 왜 그런 선택을 하시나요?
Java 의 equals 와 == 의 차이에 대해 설명해주세요. Kotlin 의 == 와 === 는 어떤 차이가 있나요?
스프링의 @Autowired 를 가급적 쓰지 말라는 이야기가 종종 들리는데 원인이 뭘까요?
final 키워드를 변수, 메소드, 클래스에 선언하는 것은 어떤 의미가 있습니까?
synchronized 를 메소드에 선언하는 것과, 특정 객체에 선언하는 것은 어떤 차이가 있습니까?
Reflection 을 유용하게 사용하는 사례를 말씀해 주세요.
JDK/JVM 은 대표적으로 OpenJDK 와 Oracle JDK 로 나뉘는데요, 업무에 어떤 JDK 를 사용하시겠습니까? 선택의 이유를 말씀해 주세요.
hashCode / equals 메소드의 역할에 대해 아시는 내용을 최대한 설명해주세요.
Java 의 Collections.unmodifiableList 같은 API 를 이용해 List 같은 collection 을 변경 불가능하게 만들 수 있습니다. 그렇다면 이 API 를 사용하면 immutability 를 달성할 수 있을까요?
다음 싱글턴 코드의 어떤 점을 개선하실 수 있습니까? (개선이 필요 없을 수도 있음 / 왜?)
class MySingleton {
private static MySingleton instance;
public static synchronized MySingleton getInstance() {
if (instance == null) {
instance = new MySingleton();
}
return instance;
}
}
java 9 이상에 도입된 추가 기능들 중 마음에 드는거 아무거나 하나만 설명해주세요.
민감한 정보를 String 으로 저장하는 것과, char[] 또는 StringBuilder/StringBuffer 같은 클래스로 저장하는 것은 어떤 차이가 있나요?
크기를 지정하지 않고 ArrayList 를 new 로 생성하면 크기 10의 ArrayList 가 생성됩니다. Array 는 크기를 넘길 수 없는데 반해 ArrayList 는 꽉 찬 List 에 element 를 추가로 더할 수 있습니다. 그렇다면 10개의 element 를 채워넣은 ArrayList 의 11번째 element 을 add 하기위해 어떤 일이 일어나는지 설명해주세요.
java.lang.String 의 hashCode 구현에 대해 고찰해 봅시다. 왜 그런 구현일지, 문제점은 없을지 이야기해주세요.
lambda 와 메소드 1개만 있는 익명 클래스 직접 선언은 문법적 차이 외에 어떤 내부적인 차이가 있을까요?
Java generics 에는 primitive type 을 쓸 수 없는 문제가 있습니다. 왜 그럴까요? 어떻게 해결할 수 있을까요?
I/O 를 Java nio 로 코딩할 때 주의점은 어떤게 있을까요?
Java 는 Pure OOP 언어가 아니라고 하는데, 왜 그런 걸까요?
java.lang.String 의 length 메소드는 정확한 결과를 반환하지 않는 경우가 종종 있습니다. 정확한 의 의미란 무엇이고, 왜 그럴까요?
Maven 이나 Gradle 이, 의존성 선언한 artifact 들을 찾는 과정에 대해 설명해주세요.
java.util.Property extends Hashtable, java.util.Stack extends Vector 같은 클래스는 상속으로 망한 대표 사례입니다. 이유를 설명해 주세요.
Spring boot 가 stereotype annotation 을 붙인 클래스들을 어떻게 찾고 bean 으로 등록하는지 그 과정을 최대한 상세하게 설명해주세요.
Spring 은 @Transactional 어노테이션 붙인 메소드를 어떻게 찾고 트랜잭션을 처리하나요? 그 내부 구현을 상세하게 설명해 주세요.
메소드에 @Transactional 을 붙이는 것과, TransactionTemplate 을 사용해 트랜잭션을 직접 제어하는 것에는 어떤 차이가 있나요? 어떤 방식을 더 선호하시는지 그 이유도 함께 설명해 주시기 바랍니다.
Kotlin
Kotlin 으로 작성한 jvm target 코드는 숨은 비용이 있습니다. 어떤 숨은 비용을 말하는걸까요? 그럼에도 불구하고 Kotlin 을 써야 할까요?
Kotlin extension function 이 실제 native code 로 바뀔 때 어떤 형태로 바뀌는지 설명해주세요.
Python
object 의 기본 메소드인 __eq__, __hash__ 에 대해 설명해 주세요. 두 메소드를 모두 구현할 때, 어떤 점을 주의해야 할까요?
Memory leak 을 유발하는 python 코딩 패턴의 사례를 말씀해주세요.
yield 키워드의 역할에 대해 설명해주세요.
Global Interperter Lock 에 대해 설명해주세요.
Node.js
Promise 에 대해 설명해 보세요.
Typescript 의 type 과 interface 의 공통점 및 차이점을 설명해 보세요.
Typescript 의 interface 의 특징? 컴파일 이후에는 어떻게 되는지 말씀해주세요.
Javascript 와 Java 의 차이를 우리 할머니도 알아들으실 수 있도록 설명해주실 수 있습니까?
Map 의 키로 number, string 대신 object 를 쓰고 싶다면, 어떤 점을 고려해야 합니까?
Prototype 기반 상속과 일반적인 OOP 에서의 상속은 어떤 차이가 있습니까?
Android
비동기로 처리한 작업을 UI 에 표시하기 위해 어떤 일이 필요한지 설명해주세요.
안드로이드 Activity 처리 결과를 다루는 onActivityResult` 메소드는 왜 deprecated 처리되었을까요?
ViewGroup 내에 선언한 View 들에 onClickListener 를 선언할 경우 안드로이드가 이벤트를 어떻게 핸들링하는지 설명해 주시기 바랍니다.
systrace 가 뭐고, 결과 분석은 어떻게?
Memory leak 을 유발하는 coding pattern?
Dagger 를 왜 쓸까요? 다른 대안은 없나요?
Android HAL(Hardware Abstraction Layer) 에 대해 설명해주세요.
ios
비동기로 처리한 작업을 UI 에 표시하기 위해 어떤 일이 필요한지 설명해주세요.
Web
비동기로 처리한 작업을 UI 에 표시하기 위해 어떤 일이 필요한지 설명해주세요.
DOM 의 class 와 id 의 차이?
Event bubbling 과 Event capturing 에 대해 설명해주세요.
웹 UI 프레임워크들은 SPA 로 개발하는게 2022년 현재 대세인데 native app 에서는 그런 방식이 일반적이지 않다. 왜 그럴까요?
flutter/RN 이 제공하는 hot reload 와 hot restart(live reload) 의 차이에 대해 설명해주세요.
scp '윈도우 계정@윈도우 IP : 파일 경로' '리눅스 디렉토리 경로'
ex)
scp hwan@x.x.x.x:/c:\users\hwan\desktop\file.txt /home/user/
정리
scp는 콘솔에서 서버로의 파일 송수신을 도와주는 도구이다.
scp의 사용을 위해서는 openssh가 설치되어 있어야하며, 서버에서는 ssh 서비스가 실행 중이어야 한다.
위 조건이 만족되면 운영체제에 상관없이 파일의 송수신이 가능하다.
# 명령어는 클라이언트에서 실행
# 클라이언트에서 서버로 파일 보내기
scp '클라이언트 내부의 파일 위치' '유저명@서버주소:파일이 위치할 서버 내부의 경로'
# 서버에서 클라이언트로 파일 가져오기
scp '유저명@서버주소:서버 내부의 파일 위치' '파일이 위치할 클라이언트 내부의 경로'
1차 : 문제에서 알려준 공식대로 구현 -> 50점, 작은 문자열에서는 잘 동작하지만 큰 문자열에서는 시간초과
2차 : 합동식 활용 A * B mod C -> (A mod C) * (B mod C) -> 통과
3. 코드
1차 코드
#include<iostream>
#include <cmath>
typedef unsigned long long ll;
using namespace std;
int main() {
int str_len;
cin >> str_len;
string str;
cin >> str;
int a, r = 31, M = 1234567891;
ll sum = 0;
for (int i = 0; i < str_len; i++) {
a = (str[i] - 'a') + 1;
sum += a * pow(r, i);
}
cout << sum % M << "\n";
}
2차 코드
#include<iostream>
using namespace std;
typedef unsigned long long ll;
int main() {
int str_len;
cin >> str_len;
string str;
cin >> str;
ll r, sum = 0, a;
int M = 1234567891;
for (int i = 0; i < str_len; i++) {
a = (str[i] - 'a') + 1;
r = 1;
for (int j = 0; j < i; j++) {
r *= 31;
r %= M;
}
sum += a * r;
sum %= M;
}
cout << sum;
}
1차 코드 : 동일한 시간일 경우 높은 높이 조건을 충족하지 못함. ( + 틀린 케이스 존재)
#include<iostream>
#include<cmath>
using namespace std;
int main() {
int n, m, inventory, height, time = 0;
double sum = 0;
cin >> n >> m >> inventory;
// 맵 입력
int** map = new int*[n];
for (int i = 0; i < n; i++) {
map[i] = new int[m];
for (int j = 0; j < m; j++) {
cin >> map[i][j];
sum += map[i][j];
}
}
// 전체 높이 결정 (인벤토리 기준)
if (inventory > 0) {
height = round(sum / (n * m));
}
else {
height = floor(sum / (n * m));
}
// 땅 다듬기
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
if (map[i][j] == height)
continue;
if (map[i][j] > height) {
time += 2;
map[i][j] -= 1;
inventory++;
}
else {
time += 1;
map[i][j] += 1;
inventory--;
}
}
}
cout << time << " " << height << "\n";
return 0;
}
2차 코드 : 틀린 케이스 존재 (앞에부터 가져와서 쌓기 때문에 블록이 부족한 경우 발생)
#include<iostream>
#include<cmath>
using namespace std;
// 현재 맵에서 입력된 높이까지 얼마의 시간이 걸리는지 반환
int func_18111_getTime(int height, int n, int m, int inventory, int **map) {
int time = 0, tmp_map;
bool flag = true;
// map 전체 스캔
for (int i = 0; i < n && flag; i++) {
for (int j = 0; j < m && flag; j++) {
tmp_map = map[i][j];
if (tmp_map == height)
continue;
// 현재 블록의 높이가 원하는 높이보다 높으면 블록 회수
if (tmp_map > height) {
while (tmp_map != height) {
time += 2;
tmp_map -= 1;
inventory++;
}
}
else {
// 블록 설치 (인벤토리가 부족하면 flag == false
while (tmp_map != height) {
if (inventory > 0) {
inventory--;
}
else {
flag = false;
}
if (!flag)
break;
time += 1;
tmp_map += 1;
}
if (!flag || tmp_map != height) {
flag = false;
break;
}
}
}
}
// flag 가 false 면 time 초기화
if (!flag) {
time = 0;
}
return time;
}
int main() {
int n, m, inventory, height=-1, time = 0, tmp, min = 2100000000, max=0;
double sum = 0;
cin >> n >> m >> inventory;
// 맵 정보 입력 및 블록 최대값 구하기
int** map = new int* [n];
for (int i = 0; i < n; i++) {
map[i] = new int[m];
for (int j = 0; j < m; j++) {
cin >> map[i][j];
if (max < map[i][j]) {
max = map[i][j];
}
}
}
// 0 ~ 블록 최대 값 중 시간이 가장 빠르고, 높이가 높은 값 찾기
for (int i = 0; i <= max; i++) {
tmp = func_18111_getTime(i, n, m, inventory, map);
if (min >= tmp && tmp > 0) {
if (min == tmp && height > i) continue;
min = tmp;
height = i;
}
}
// 찾을 수 없으면 0으로 초기화
if (min == 2100000000 || height == -1) {
min = 0;
height = 0;
}
cout << min << " " << height << "\n";
return 0;
}
3차 코드 : 입력 높이(height)보다 높은 블록들 먼저 회수하고, 낮은 블록 쌓기
#include<iostream>
#include<cmath>
using namespace std;
int func_18111_getTime(int height, int n, int m, int inventory, int **map) {
int time = 0, tmp_map;
bool flag = true;
// 블록 회수 (높이 낮추기)
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
tmp_map = map[i][j];
if (tmp_map == height)
continue;
if (tmp_map > height) {
while (tmp_map != height) {
time += 2;
tmp_map -= 1;
inventory++;
}
}
}
}
// 블록 설치 (부족하면 flag == false)
for (int i = 0; i < n && flag; i++) {
for (int j = 0; j < m && flag; j++) {
tmp_map = map[i][j];
if (tmp_map == height)
continue;
if (tmp_map < height) {
while (tmp_map != height) {
if (inventory > 0) {
inventory--;
}
else {
flag = false;
}
if (!flag)
break;
time += 1;
tmp_map += 1;
}
if (!flag || tmp_map != height) {
flag = false;
break;
}
}
}
}
if (!flag) {
time = 0;
}
return time;
}
int main() {
int n, m, inventory, height=-1, time = 0, tmp, min = 2100000000, max=0;
double sum = 0;
cin >> n >> m >> inventory;
int** map = new int* [n];
for (int i = 0; i < n; i++) {
map[i] = new int[m];
for (int j = 0; j < m; j++) {
cin >> map[i][j];
if (max < map[i][j]) {
max = map[i][j];
}
}
}
for (int i = 0; i <= max; i++) {
tmp = func_18111_getTime(i, n, m, inventory, map);
if (min >= tmp && tmp > 0) {
if (min == tmp && height > i) continue;
min = tmp;
height = i;
}
}
if (min == 2100000000 || height == -1) {
min = 0;
height = 0;
}
cout << min << " " << height << "\n";
return 0;
}
4차 코드 : 통과
#include<iostream>
#include<cmath>
using namespace std;
int main() {
int n, m, inventory, min = 2100000000, max = 0;
int height = -1, time = 0, tmp_block, time_min= 2100000000;
double sum = 0;
cin >> n >> m >> inventory;
// 맵 입력
int** map = new int* [n];
for (int i = 0; i < n; i++) {
map[i] = new int[m];
for (int j = 0; j < m; j++) {
cin >> map[i][j];
if (max < map[i][j]) {
max = map[i][j];
}
if (min > map[i][j]) {
min = map[i][j];
}
}
}
int build_block, remove_block;
// 맵의 최소 블록 높이부터 가장 높은 블록까지 반복
for (int h = min; h <= max; h++) {
build_block = 0;
remove_block = 0;
// h에서의 회수할 블록, 설치할 블록 개수 구하기
for (int i = 0; i < n; i++) {
for (int j = 0; j < m; j++) {
tmp_block = map[i][j];
// 현재 블록이 h보다 낮으면 설치할 블록 개수 누적
if (h > tmp_block) {
build_block += h - tmp_block;
}
// 현재 블록이 h 보다 높으면 회수할 블록 개수 누적
if (h < tmp_block) {
remove_block += tmp_block - h;
}
}
}
// 설치할 블록 개수가 인벤토리와 회수한 블록의합보다 부족한지 검사
if (build_block <= remove_block + inventory) {
time = remove_block * 2 + build_block;
if (time_min >= time) {
if (height > h) continue;
time_min = time;
height = h;
}
}
}
cout << time_min << " " << height << "\n";
return 0;
}
#include <iostream>
#include <vector>
using namespace std;
typedef unsigned long long ll;
int func_1009_mod(int a, int b) {
vector<int> tmp, tmp2;
int *x;
ll res = 1;
while(b!=0) {
tmp.push_back(b % 2);
b /= 2;
}
x = new int[21];
x[0] = a % 10;
for (int j = 1; j <= 20; j++) {
x[j] = (x[j-1] * x[j - 1]) % 10;
}
for (int i = 0; i < tmp.size(); i++) {
if (tmp.at(i) == 1) {
res *= x[i];
}
}
if (res % 10 == 0) res = 10;
else res %= 10;
return res;
}
int main() {
int n, a, b;
cin >> n;
for (int i = 0; i < n; i++) {
cin >> a >> b;
cout << func_1009_mod(a, b) << "\n";
}
return 0;
}
4. 결과
C++로 구현시 큰 수를 변수 하나로 처리하기 어려워 다른 방법을 찾아야했지만, 파이썬을 활용하면 Pow 연산만으로 결과를 구할 수 있음
using System;
using System.Collections.Generic;
using System.Linq;
using System.Text;
using System.Threading.Tasks;
using System.Windows;
using System.Windows.Controls;
using System.Windows.Data;
using System.Windows.Documents;
using System.Windows.Input;
using System.Windows.Media;
using System.Windows.Media.Imaging;
using System.Windows.Navigation;
using System.Windows.Shapes;
namespace youtube_viewer
{
/// <summary>
/// MainWindow.xaml에 대한 상호 작용 논리
/// </summary>
public partial class MainWindow : Window
{
CefSharp.Wpf.ChromiumWebBrowser _browser;
string str;
public MainWindow()
{
InitializeComponent();
_browser = new CefSharp.Wpf.ChromiumWebBrowser();
GridViewer.Children.Add(_browser);
}
private void btn_play_Click(object sender, RoutedEventArgs e)
{
str = txtbox_url.Text.Split('=')[1].Split('&')[0];
if (this._browser != null)
{
_browser.Address = $"https://www.youtube-nocookie.com/embed/{str}";
}
}
}
}