function tar_xvzf() {
local File=$1.tar.gz
local Dir=`echo $File | sed 's/.tar.gz//g'`
if [[ ! -d $Dir ]]; then
#echo $Dir " - not exist"
if [[ ! -f $File ]]; then
#echo $File " - exist"
echo "<Start Release - $File >"
tar -xvzf $File
echo "<End Release - $File >"
fi
fi
#echo ""
}
tar_xvzf "test*"
만약 PC와 모니터가 2대씩 있을 때 각 PC를 둘 다 듀얼 모니터로 사용하고 싶다면 어떻게 하는게 좋을까? 가장 쉽게 문제를 해결하려면 매번 사용하는 PC의 HDMI 케이블을 바꿔서 연결하면 된다!
만약 그것도 귀찮다면 KVM 스위치를 구매해 연결해두고 필요한 PC의 버튼이나 단축키를 눌러서 사용하면 된다. (망 분리 환경이라면 보통 Aten과 같은 회사의 보안 인증이 된 제품을 지급해준다. 하지만 개인이 구매하기 어렵고 비싸다..!) 하지만 PC를 사용하다보면 양쪽 PC를 동시에 활용해야하는 경우가 꽤 많았고 개인적으로 KVM에서 듀얼 모니터 설정이 더 어려웠던 것 같다.
차라리 아래처럼 케이블을 전부 연결해두고 모니터 버튼으로 필요할 때마다 입력소스를 바꿔주는게 더 편하다.
많이 편해졌지만 여전히 몸을 움직여 버튼을 눌러야 하고 만약 PC 1을 듀얼로 사용하던 중에 PC 2를 듀얼로 사용하려면 버튼을 두번 눌러야 한다.
여러 대의 PC를 하나의 인터페이스로 다루는 KVM과 사용자의 편의를 위한 듀얼 모니터를 최소의 움직임으로 사용할 순 없는 걸까?
프로그램을 만들어보기로 했다.
MCCS, DDC/CI, VCP Code
MCCS (Monitor Control Command Set)는 모니터 제어 명령 세트로 VESA (Video Electronics Standards Association)에서 개발한 컴퓨터 디스플레이 표준이다. 보통 PC나 셋탑박스 같은 장치에서 모니터를 제어하기 위한 바이너리 프로토콜로 사용되지만, 해당 글에서는 프로그램 제작을 위해 사용하려고 한다.
MCCS를 활용하면 DDC/CI (Display Data Channel/ Command Interface)와 VCP (Virtual Control Panel) 코드를 통해 모니터에 명령을 보낼 수 있다.
VCP 코드는 가상 제어 패널의 약어로 아래 이미지와 같은 표준 명령어 타입을 따른다.
VCP 코드
정해진 값을 약속된 프로토콜로 모니터에 명령을 전달하면 모니터가 해당 동작을 수행한다. 예를 들어 VCP 코드로 0xD6을 넣어주면 모니터의 전원이 On/Off되고, 0x60을 전달하면 모니터의 입력 소스가 변경된다.
현재 만들어지는 모니터는 대부분(거의 전부) 해당 표준을 따르기 때문에 코드만 잘 전달하면 정말 편할 것 같다..! 근데 모니터에 코드를 어떻게 전달하라는 걸까?
여러 방식이 있겠지만 난 보통 윈도우를 많이 사용하기 때문에 exe 프로그램을 제작하기로 했다. Windows API를 통해 모니터로 VCP 코드를 보내보자.
모니터 제어 API
일반적으로 모니터와 관련된 API를 검색하면 모니터의 핸들을 얻어오거나 정보를 얻어오기 위해 MONITORINFOEXA와 같은 구조체나 GetMonitorInfo()와 같은 함수를 사용한다. 하지만 제어를 위해서는 DDC/CI 프로토콜에 맞춰서 모니터로 데이터를 보내주어야 한다.
MCCS 표준을 따르면 모니터 버튼으로 할 수 있는 동작 대부분을 프로그램으로 수행할 수 있지만 지금은 모니터 입력 소스만 정확하게 변경하면 된다.
위에서 VCP 코드를 DDC/CI 프로토콜에 따라서 모니터로 보내주기만 하면 기능이 수행된다고 했었다. 그런데 MSDN을 보면 API들은 내부적으로 DDC/CI를 사용하여 모니터에 명령을 보내준다고 되어 있기 때문에, VCP 코드만 제대로 맞춰서 전달해주면 될 것 같다.
이제 VCP 코드를 내가 원하는 모니터로 전달해주는 방법을 찾아야된다.
High-Level/ Low-Level Monitor 구성 함수
위 MSDN 링크에 들어가보면 High-Level과 Low-Level로 나뉘어진 함수들을 볼 수 있는데, 이 중 나에게 필요한 내용은 VCP 코드를 다룰 수 있는 Low-Level 함수들이다.
MSDN의 Low-level Monitor 함수 사용법
대충 윈도우에서 감지한 모니터들을 알려주는 Enum 함수와 VCP 관련된 함수들을 알려주는데, 8번의 SetVCPFeature 함수가 눈에 띄였다.
SetVCPFeature 함수는 위와 같은 형태로 되어 있다. Enum 함수 등으로 얻어온 모니터의 핸들을 구해서 넣고 원하는 VCP Code 값을 넣으면 될거 같다. 이제 변경을 원하는 모니터와 원하는 VCP 기능을 전달하는 방법은 알았다.
그런데 우리의 상황처럼 1개의 모니터에 연결된 케이블이 여러 개라면 원하는 케이블은 어떻게 설정해야 되는 걸까?
이 방법을 알기 위해 엄청난 검색을 했는데.. 방법은 의외로 간단했다. 3번째 인자인 dwNewValue에 해당 케이블의 값을 넣어주면 된다! 그렇다면 그 값은 어떻게 알 수 있을까??
다시 엄청난 삽질이 시작됐다.
GetVCPFeatureAndVCPFeatureReply() 함수
온갖 키워드와 방법으로 검색해 알게된 방법은 GetVCPFeatureAndVCPFeatureReply() 함수를 사용하는 것 이었다. 그런데 위의 MSDN 이미지의 7번을 자세히 보면 이미 설명이 잘 되어 있다. MS에선 처음부터 전부 다 알려주었지만 내가 이해를 못했을 뿐이다. (멍청하면 손발이 고생한다..)
함수를 살펴보면 먼저 SetVCPFeature 함수와 비슷하게 모니터의 핸들과 VCP 코드를 요구한다. 그리고 3, 4번째 인자를 통해 Current Value 값과 Maximum Value 값을 얻어 낼 수 있었다. (cf. 일반적으로 return을 통해 함수의 결과를 받지만 return으로는 하나의 값만 반환받을 수 있기 때문에 포인터 형태로 비어있는 변수를 전달해주면 알아서 채워준다.)
위의 함수를 잘 사용하면 모니터에 연결되어 있는 케이블들의 Value 값을 구할 수 있다. (HDMI, DP, VGA등에 따라 값이 다르다.)
이제 SetVCPFeature() 함수를 사용하는데 필요한 모든 데이터를 구했다.
하지만 아직 마지막 한 가지 문제가 남아있다. 모니터의 제조사나 모델마다 해당 Value의 값이 다르다는 것이다ㅋㅋ (예를 들면 A사의 A1 모니터는 HDMI의 Value가 10이고, B사의 B1모니터는 101이다. 심지어 같은 제조사의 다른 제품일 경우도 값이 다른 경우가 있었다.)
위의 API들을 잘 조합하면 자동으로 구할 수 있을 것 같았지만, 더 삽질하면 주말동안 끝내지 못할 것 같아 모니터들의 값을 알아낸 뒤 그냥 하드코딩했다.
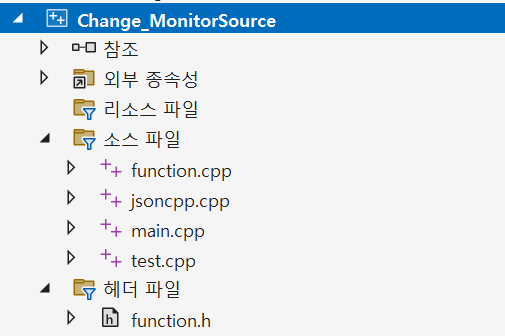
개발 환경은 Visual Studio Community 2022이고 프로젝트는 아래 이미지처럼 구성했다.
jsoncpp.cpp는 c++에서 json 파싱을 위해 나중에 추가한 라이브러리 코드이고 test.cpp는 테스트 함수를 작성해둔 파일이라 생략했다. 그리고 사실 EnumDisplayMonitors 함수는 MonitorEnumProc라는 콜백 함수를 내부에서 호출하기 때문에 SetVCPFeature 함수를 사용하기 위해서 콜백 함수들을 작성해야 하는데, 해당 내용들은 나중에 시간되면 추가로 작성해보겠다.
코드는 돌아가게만 만들어 두었기 때문에 정리도 잘 안되어 있지만 이것도 나중에 정리하기로 하고 일단 올려보겠다.
function.h 코드
#pragma once
#pragma warning(disable: 28251)
// api 헤더
#include <windows.h>
#include <winuser.h>
#include <Shlwapi.h>
#define VC_EXTRALEAN
#define _WIN32_WINDOWS 0x0500
// library
#pragma comment(lib, "dxva2")
#pragma comment(lib, "user32")
#pragma comment(lib, "Shlwapi.lib")
// 모니터 vcp 관련 헤더
#include <lowlevelmonitorconfigurationapi.h>
#include <PhysicalMonitorEnumerationAPI.h>
#include <HighLevelMonitorConfigurationAPI.h>
// c++ 헤더
#include <iostream>
#include <fstream>
#include <string>
#include <vector>
#include "json/json.h"
using namespace std;
// 구조체
typedef struct _MONITORPARAM
{
LPCWSTR szPhysicalMonitorDescription;
BYTE VCPcode;
int source;
BOOL bPowerOn;
int curVal;
} MONITOR_PARAM, * PMONITOR_PARAM;
typedef struct _GETMONITORINFO
{
LPCWSTR szPrimaryMonitorDescription;
LPCWSTR szSecondMonitorDescription;
int curVal;
int curVal_second;
} GET_MONITOR_INFO, * GET_PMONITOR_INFO;
// 얘를 모니터 개수만큼 포인터 배열로 만들어서 _getCurrentValue에 전달하면, 모니터 돌면서 정보를 채워줌.
typedef struct _MONITOR{
int num;
char * monName;
BYTE vcpValue;
} MONITOR, * PMONITOR;
// test 함수
VOID test_setInputSource(HWND, DWORD);
VOID test_getPrimaryMonitor(HWND);
VOID test_setInputSource(HWND, DWORD);
VOID test_SetMonitorPower(LPCWSTR, BOOL);
// interface 함수
VOID ChangeMonitorInput_hwan(PMONITOR mon, int monNum);
VOID GetMonitorInfo_hwan(PMONITOR mon, int monNum);
// callback 함수
BOOL CALLBACK MonitorEnumProc(HMONITOR, HDC, LPRECT, LPARAM);
BOOL CALLBACK _getCurrentValue(HMONITOR, HDC, LPRECT, LPARAM); // 얘가 모니터 정보 얻어와줌
BOOL CALLBACK _setMonitorInput(HMONITOR, HDC, LPRECT, LPARAM); // 얘는 특정 모니터에 value값 넣어줌.
// json 함수
void load_json(LPCWSTR file_path, PMONITOR mon, int monNum);
void save_json(LPCWSTR file_path, int monNum, Json::Value *monitor);
프로그램을 시작할 때 동일 경로 상의 vcp.json 파일 존재를 기준으로 mode를 정하는데, 해당 mode가 활성화 되어 있을 경우 UI는 나타나지 않고 vcp.json에 정의된 대상으로 변경만 수행한 뒤 프로그램을 종료한다. (최초에 한번 값을 넣어두면 다음부턴 실행했을 경우 모니터가 원하는 대상으로 변경된다. 개인적으로는 아래 작업 표시줄에 바로가기를 등록해두고 필요할때 눌러서 사용했다.)
여기에 등록해서 누르면 모니터가 바뀜
아래는 최초 실행 시 나오는 프로그램의 UI이다.
최초 실행 시 UI
현재는 연결된 모니터가 없어 노트북의 내장 모니터인 Generic PnP Monitor만 나오지만 다른 모니터가 연결되어 있을 경우, Dell H00000 (DP) 와 같은 식으로 모니터의 이름이 나온다. (제대로 나오지 않을 경우 장치 관리자의 모니터 탭에서 확인할 수 있다.)
참고로 이 부분이 모니터 개수만큼 아래로 늘어난다.
프로그램에서는 해당 문자열을 1번에 입력하여 여러개의 모니터들 중 변경을 원하는 대상을 구분할 수 있고 2번에는 연결된 케이블의 Value을 입력하여 원하는 케이블을 선택할 수 있다.
입력 후 Set 버튼을 누르면 모니터가 변경되고, Save를 누르면 동일 경로에 입력된 값으로 vcp.json 파일이 생성된다 이후 프로그램을 종료하면 실행 시 마다 vcp.json 내의 값을 기준으로 모니터가 변경된다. 만약 값 변경을 원하면 vcp.json을 직접 수정하거나 파일을 삭제하고 프로그램을 재실행해서 입력해주면 된다.
추가로 Value를 구하는 방법이 궁금하면 위의 GetVCPFeatureAndVCPFeatureReply() 함수를 잘 활용해서 구해보기 바란다.. (만약 귀찮으면 1부터 Max까지 값을 직접 넣어보면서 바뀌는 값을 찾는 방법도 있다.)
결과 및 느낀점
회사에 다니면서 주말 프로젝트로 간단하게 생각하고 진행했었는데, 자료를 찾다보니 점점 내용이 많아졌다.
어쨋든 기능적으로 나름 잘 돌아가는 프로그램을 만들었고 회사에서도 잘 사용을 하고 있기 때문에 마무리는 했지만, 중간에 작성했던 유용한 테스트 함수들이 계속 수정되면서 사라져 추가하지 못한 기능들이 많아 아쉬운 점이 많다. (Value 찾아주는 함수 등)
나중에 좀 더 기능을 추가해서 깔끔하게 업그레이드된 프로그램을 만들면 좋을 것 같다.
추가로 ddcutil? 라이브러리를 사용하면 dll을 통해 더 정리가 잘된 함수들을 사용할 수 있고 커맨드 형식으로도 제공이 되는 것 같다. (API로 삽질하지 말고 라이브러리 사용하면 편하다..) https://www.ddcutil.com/
** 아래 글은 개인의 조사를 바탕으로 주관적으로 작성되었습니다. 잘못된 부분은 댓글로 남겨주시면 수정하겠습니다.
XP ?
계획/ 피드백 루프
XP(익스트림 프로그래밍)은 애자일 방법론의 유형 중 하나로 미국의 소프트웨어 엔지니어인 캔트 벡이 제안한 소프트웨어 개발 방법론이다.
비즈니스 상의 요구사항이 계속해서 바뀌는 경우에 사용하면 효율적인 개발 방법이며, XP라는 약칭으로 불린다.
XP는 5가지의 가치와 12개의 기본 원리(또는 실천 방법)와 1~3주 정도의 반복 주기(Iteration)가 존재하며, 개발 문서 보다는 소스 코드를 조직적인 개발의 움직임 보다는 개개인의 책임과 용기에 중점을 둔다.
또한 12가지 기본 원리 중 하나인 테스트 기반 개발(TDD; Test Driven Develop)를 통해 프로그래머들이 코딩 전에 테스트 코드를 작성하기 때문에 반복적인 프로토 타입의 전달 시에 버그가 상대적으로 적은 데모를 경험할 수 있게 해준다.
켄트 백은 XP를 이끄는 가치와 원칙에 대해서도 강조했다.
실천 방법에만 집중하고 가치와 원칙을 무시한다면, XP를 제대로 실천하고 있다고 하기는 어렵다고 생각한다.
아래에서는 각 가치와 원칙을 정리해보겠다.
XP의 5가지 가치
xp에서는 아래 5가지의 가치를 추구한다.
용기 (Courage)
단순성 (Simplicity)
의사소통 (Communication)
피드백 (Feedback)
존중 (Respect)
가치의 실현을 위해서는 자신감있게 개발하고 빠르게 피드백하며, 테스트에 부합하지 못할 경우 코드를 리펙토링(용기)할 수 있도록해야 한다. 또한 단순성을 위해서 필요한 최소한의 작업만을 해야하고 개발자-관리자-고객 간의 원활한 소통(의사소통)을 하여 소통에 대한 빠른 피드백을 전달해야 한다.
마지막으로는 팀원 서로간의 상호 존중해야 한다.
XP의 12가지 기본 원리
XP에는 12가지의 기본 원리가 존재한다.
짝 프로그래밍 (Pair Programming)
공동 코드 소유 (Collective Ownership)
지속적인 통합 (CI; Continuous Intergration)
계획 세우기 (Planning Process)
작은 릴리즈 (Small Release)
메타포어 (MetaPhor)
간단한 디자인 (Simple Design)
테스트 기반 개발 (TDD; Test Driven Develop)
리팩토링 (Refactoring)
40시간 작업 (40-Hour Work)
고객 상주 (On Site Customer)
코드 표준 (Coding Standard)
먼저 짝 프로그래밍은 개발자 2인이 짝으로 코딩한다는 원리이다.
시스템에 있는 코드는 누구나, 언제나 수정이 가능(공동 코드 소유)해야하며 매일 여러번씩 소프트웨어를 통합하고 빌드(CI)해야한다.
XP에서는 고객이 요구하는 가치를 정의하고 개발자가 필요한 내용이 무엇인지, 어떤 부분에서 지연될 수 있는지를 알려주어야한다.(계획 세우기) 또한 작은 릴리즈를 위해서는 작은 시스템을 먼저 만들고, 짧은 주기로 업데이트 해야한다.
공통적인 이름 체계와 시스템 서술서를 통해 고객과 개발자의 의사소통을 원활하게 하며 (메타포어), 간단한 디자인은 현재의 요구사항에 적합한 가장 단순한 시스템을 설계한다는 원리이다.
테스트 기반 개발(TDD)은 위에서도 잠깐 언급했지만, 다른 애자일 방법론과 차이를 두게 하는 중요한 부분이다.
개발자는 TDD를 위해 작성해야 하는 프로그램에 대한 테스트를 먼저 작성해야하며, 이 테스트를 통과할 수 있도록 실제 프로그램의 코드를 작성해야 한다.
리팩토링은 프로그램의 기능을 변경하지 않으면서 중복을 제거하고 기능을 단순화하는 등의 최적화에 대한 내용이고 40시간 작업은 말 그대로 주 40시간 미만의 작업을 통해 개발자의 피로도를 관리하여 실수를 줄인다는 의미이다.
고객상주는 개발자의 질문에 즉각 대답해 줄 수 있는 고객을 프로젝트에 풀타임으로 상주시켜야 한다는 의미이고, 마지막 코드 표준은 효과적인 공동작업을 위해 모든 코드에 대한 코딩 표준을 정의해야 한다는 원리이다.
정리 및 느낀점
애자일 방법론의 여러 유형 중 하나인 XP에 대해서 정리해보았다.
기존의 여러 전통적인 방법론들(폭포수, 나선형 모델)과 비교하면 훨씬 복잡하지만 위의 기본 원리들이 잘 실행되고 가치들도 잘 지켜진다면, 기존의 단점을 없애면서도 생산성과 결과물의 완성도 등을 높일 수 있는 획기적인 방법이라는 생각이 들었다.
하지만 각 가치를 추구하면서도 12가지 기본 방법들을 지켜나가려면 팀원 개개인과 고객, PM등 프로젝트의 구성원 모두가 XP에 대해서 잘 이해하고 있어야하고, 원칙과 가치만 존재하기 때문에(같은 용어여도 사람마다 생각하는 게 다를 수 있을 것 같다.) 현실의 프로젝트에 적용하기는 쉽지 않겠다는 생각이 들었다.
** 아래 글은 개인의 조사를 바탕으로 주관적으로 작성되었습니다. 잘못된 부분은 댓글로 남겨주시면 수정하겠습니다.
MSA (Micro Service Architecture) ?
DevOps를 공부하면서 MSA라는 단어를 많이 듣게 되었다.
처음 단어를 들었을 때는 별로 깊게 생각하지 않았었기 때문에 (다시 생각해보면 조금 부끄럽지만) AWS와 GCP와 같은 클라우드 플랫폼을 말하는 거라고 생각했었다. 하지만 우연히 다시 검색해본 MSA의 설명은 충격적이었다.
MSA : Micro Service Architecture
기존의 MA(Monorithic Architecture)는 모든 모듈이 하나의 서비스 내에 종속되어 있다.
이런 구조는 프로젝트의 개발과 빌드, 배포 등의 작업에 장점이 있지만, 만약 출시된 프로그램에 새로운 기능이 추가된다면 해당 모듈 하나를 적용하기 위해 모든 서비스를 다시 빌드하고, 배포해야 한다.
또한 추가된 기능이 기존의 프로젝트 구조와 맞지 않다면, 하나의 기능을 추가하기 위해 프로젝트 전체를 뜯어 고쳐야할 수 도 있다.
하지만 MSA는 각 기능을 독립적으로 분리하여 (단일 컴포넌트) 여러 서비스의 조합으로 하나의 시스템을 구축하며 각각의 서비스가 의존적이지 않기 때문에(API 기반) 변경이 필요한 하나의 모듈만을 수정 후 배포할 수 있다. 또한 이런 특성으로인해 각 서비스의 확장도 간단하다.
MSA에서의 조직 구조와 단점
기존의 개발 조직 구조는 기능(또는 소프트웨어 생명주기의 단계)과 역할을 기준으로 기획, 개발, 운영 등의 팀을 나누어 하나의 시스템을 이루었다. 이러한 방식은 인력관리와 운영 등의 관점에서는 효율적이지만, 각 조직간의 커뮤니케이션과 협업을 통한 생산성과 변화에 대한 대응 등의 관점에서는 비효율적이었다.
MA와 MSA
MSA에서의 조직 구조는 각각의 팀이 하나의 서비스를 맡는다.
각 팀은 서로간의 의존성이 적기때문에 각 서비스의 확장, 변경등의 지속적인 개발과 유연한 운영이 가능하고 요청에 대한 피드백이 빨라진다. 하지만 MSA에도 단점이 많다.
우선 MSA 자체는 여러 독립적인 서비스가 이루어져 하나의 시스템을 원활하게 운영해야 하기 때문에 최대한 방어적인 코딩이 필요하고 각 서비스마다 DB가 존재할 경우 분리된 DB들 간의 트랜젝션과 데이터의 동기화 문제가 존재하며 각 서비스가 도메인과 API를 기반으로 통신하기 때문에 인터페이스의 개발에도 신경을 써야한다. 또한 통합 테스트와 배포가 어려울 수 있다. 조직의 관점에서도 인력을 관리하기 어려워지고, 개발자들은 인프라에 대한 운영과 각 서비스에 대한 테스트도 진행해야한다.
팀원 개개인의 숙련도가 중요해질 수 밖에 없는 구조이다.
MSA 단점의 보완
MSA에서의 단점인 분리된 여러 DB 문제와 통합테스트, 배포에 대한 부분은 AWS, GCP와 같은 클라우드 서비스와 쿠버네티스가 등장하면서 많은 부분이 상쇄되었다.
쿠버네티스에서는 pod의 형태로 각 컴포넌트, 서비스들을 관리하며 배포와 테스트 자동화를 구축할 수도 있다.
또한 각 서비스 간의 (인그레스를 통한 도메인 중심의) 통신을 지원하기 때문에 DB와 데이터를 하나의 pod 형태로 관리할 수 있다.
그 결과로 결합도가 낮아져 설계 구조의 변경도 비교적 쉬워졌고 변화에 대한 대응과 확장도 용이해졌으며 그 외의 다양한 단점들도 많은 부분이 상쇄되었다.
팀원 개개인의 숙련도만 충분하다면 기업 입장에서는 MSA를 선택하지 않을 이유가 없다고 생각한다.
CallBack 함수는 일반적인 함수와 비슷하지만, 호출되는 시점이 시스템(이벤트)에 의해 결정된다는 차이가 있다.
윈도우 API를 공부하면 가장 처음 배우는 Window를 띄우는 코드(링크)에서도 콜백 함수인 윈도우 프로시져를 볼 수 있는데, 해당 콜백함수(프로시져)는 WinMain에서 WndClass.lpfnWndProc=WndProc; 로 WNDCLASS 구조체에 등록된 뒤에 RegisterClass(&WndClass); 되어진 이후 따로 호출하지 않는다.
1. 기술 면접 : 직무 관련 부분으로 해당 기술 팀의 팀장 등 실무자와 면접을 진행한다. 2. 임원 면접 : 회사의 임원진과 진행하는 면접으로 인성과 태도, 조직과의 융화도에 초점을 둔 인성 면접이라고 생각 할 수 있을 듯 하다.
구조화 면접 : 면접관의 경험과 판단에 의한 면접은 확증편향으로 인한 잘못된 판단의 위험이 있다. 이런 문제를 해결하기 위해 지원자에게 미리 체계적으로 구조화된 질문을 던져 답변하는 방식을 기반으로 판단하는 구조화 면접을 기반한 채용 과정들이 도입된다. 아래는 구글이 생각하는 구조화 면접의 요소들이라고 한다.
1. 직무와 관련된 검증된 질 좋은 질문들 2. 면접관들의 기록 (지원자의 답변에 대해 종합적인 피드백 등) 3. 모든 평가자들이 표준화된 기준에 따라 점수를 받음 4. 면접관 교육
예상 질문 및 답변 ( 사람인 참고 )
간단하게 자기소개 먼저 해주세요 (1분 자기소개) 또는 지원동기가 무엇인가요?
이 회사에 적합한 인재라고 생각하는 이유가 있나요?
살면서 가장 힘들었던 경험이 무엇이고 있다면 어떻게 극복했나요?
갈등이나 불화를 겪은 경험이 있나요? 있다면 어떻게 해결했나요?
남들과 차별화되는 강점이 무엇인가요?
(공백기가 있다면) 공백기 동안 무엇을 했나요?
지원 직군에 가장 중요한 역량은 뭐라고 생각하나요?
전 직장에서 가장 크게 기여한 부분이 무엇인가요?
이전 직장에서 이해관계자들과의 관계를 어땠나요?
우리 회사의 경쟁사를 알고 있나요??
(첫 이직 또는 이직횟수가 적은 경우) 이직에 대한 계기, 그만둔 이유 ** 회사가 해결해 줄 수 없는 문제 제시 (학업, 가정사, 개인사, 업무발전 등)
다른 회사에 갈 수도 있었는데, 우리 회사에 오고 싶은 이유는?
우리 회사에 대해서 어떻게 생각 하나요?
입사 후 바라는 점이 있나요? (또는 입사 후 포부가 뭔가요?)
본인의 꿈이 뭔지 설명해 줄 수 있나요?
회사에서 어떤 걸 얻고 싶은지, 어떤 사람이 되고 싶은지 설명해줄 수 있나요 ?
회사 상품을 보면서 느낀 생각이 있나요? 우리 회사의 강약점이 뭐라고 생각하나요?
우리 회사의 경쟁력이 뭐라고 생각하나요?
야근에 대해서 어떻게 생각하나요?
상사와 의견대립이 있다면 어떻게 할 건 가요?
마지막으로 질문하고 싶은건 없나요? ** 회사에 대한 나의 적극성과 관심도 표현하기
구조화 면접 질문
대인관계 능력
어떤 일에 있어 다른사람들을 설득하여 목표를 이뤄낸 경험이 있나요?
다양한 상황이나 환경에 잘 적응한다는 걸 설명할 수 있는 경험이 있나요?
같이 일하는 사람들과 갈등이 있었던 적이 있나요? 있었다면 어떻게 행동했고 결과는 어땠나요?
당신은 주로 어떤 방법으로 갈등을 조절하나요? 갈등을 성공적으로 조정한 사례를 소개해주세요.
상대방과 협상했던 경험 중 가장 어려웠던 적이 있으면 소개해주세요. 당신은 어떻게 했고, 협상 결과는 어땠나요?
직무 수행 능력
동시다발적으로 일어난 일들을 처리해야 했던 경험과 해결했던 방법을 알려주세요.
살면서 중요한 결정을 내려야 했던 경험이 있나요? 있다면 한가지만 예로 들어주고, 현재엔 어떤 영향이 있는지도 말해주세요.
직무 분야에서 성장하기 위해 지난 2년간 노력했던 것 들을 2 가지 소개해주세요.
당신이 했던 일이 부정적인 피드백을 받았던적이 있나요?
자기개발을 위해 지금 하고 있는게 있나요?
미리 잠재적인 문제가 발생할 것을 예상하여 예방적 차원의 조치를 했던 경험이 있나요?
올바른 판단력과 논리적인 사고를 통해 문제를 해결했던 사례가 있다면 구체적으로 말해주세요.
유연성/ 적응력
지난 2년간 당신이 업무를 수행하며 변화를 주어야했던 것이 있다면 소개해주세요.
다른 사람을 변화시켜야 할 책임이 있었던 상황이 있나요? 있다면 어떤 역할을 수행했고 결과는 어떤가요. 다시 돌아간다면 다른 방법을 시도할 건가요?
지난 기간동안 이뤄낸 주된 변화가 있나요? 있다면 어떻게 이뤄냈나요?
프로젝트를 수행하면서 난관에 봉착했던 경험을 말해주세요. 어떻게 극복했나요.
시스템적 사고
현재 수행하는 업무가 조직의 임무와 목표를 달성하는데 어떤 영향을 주고 있다고 생각하나요.
당신의 현재 업무가 조직에 중요하다고 생각하나요? 그렇다면 왜 그렇게 생각하는지 알려주세요.
당신에게 기대된 수준 이상으로 직무를 수행한 경험이 있다면 알려주세요. 어떤 계기로 추가적인 노력을 하게 되었나요? 다른 동료들도 자발적으로 추가적인 노력을 한 걸 알고 있나요? 알고있었다면 피드백이 있었나요?
당신이 속한 조직이나 직무 영역의 성과를 높이기 위해 이루어낸 변화가 있다면 설명해주세요. 어떻게 그 아이디어를 떠올리게 되었고 실행을 위해 어떻게 했나요?
조직내에서 했던 결정이 조직 외적으로 의도치 않은 결과를 가져온 적이 있나요?
비전/ 목표
입사 후 포부가 무엇입니까?
입사 5년 후, 10년 후 자신의 모습은 어떨 것이라고 생각합니까?
본인의 직업관은 무엇입니까?
당신에게 일이 왜 중요합니까?
직장은 어떤 면을 보고 선택합니까?
일하는 목적이 무엇입니까?
과거 근무 경험에서 가장 크게 배운 점은 ?
어떤 회사가 훌륭한 회사라고 생각합니까?
인생에서 가장 필요한 사항은 무엇이라 생각하나요?
중소기업을 선택한 이유가 무엇입니까?
바람직한 사원상은 무엇이라고 생각합니까?
일과 사생활에 대해서 어떻게 생각합니까?
인생의 목표는 무엇입니까?
회사 근무를 하면서 가장 중요하다고 생가가하는 것은 무엇입니까?
기업의 사회적인 책임은 무엇이라고 생각합니까?
어떤 아이템을 가지고 어떤 일을 해보고 싶습니까?
본인이 리더로 추진했던 일이 있습니까? 있다면 어떤 성과가 나왔는지 말해보세요.
본인은 따라가는 스타일입니까, 아니면 주도하는 스타일입니까?
자신의 능력을 벗어난 업무가 주어진다면 어떻게 하겠습니까?
인생에서 가장 열정적인 순간은 언제였습니까?
어린 시절의 꿈이 있습니까?
인생 최종 목표(또는 꿈)은 무엇입니까?
조직적응력
어떤 경영 스타일일 때, 자신의 능력이 최대가 되나요?
상사의 말이 확실히 틀렸을 다면 어떻게 할건가요?
본인 만의 커뮤니케이션 방법이 있나요?
집안이 무너질 때 도와줄 친구는 몇 명인가요?
직원으로서 필요한 덕목이 무엇이라고 생각합니까?
입사 후 회사와 맞지 않는다면 어떻게 하시겠습니까?
어떤 유형의 사람을 싫어하나요?
어울리기 힘들었던 사람과 공동의 이익을 만들 수 있었던 경험이 있다면, 그 경험에 대해서 말해주세요.
조직에서 무언가 성취해본 경험이 있나요?
어떤 상황에서 스트레스를 받나요?
본인의 업무스타일은 어떤 유형인가요?
업무강도가 센 편입니다. 괜찮습니까?
상사와 의견이 다를 때는 어떻게 대처할 건가요?
상사가 부당한 업무지시를 시킨다면 어떻게 할 건가요?
남이 하기 싫어하는 일을 한 경험을 말해보세요.
노래방에서 몇시간이나 놀 수 있나요?
거래처와의 갈등이 있을 경우 어떻게 대처하겠습니까?
고객이 불만사항을 제기하면 어떻게 해결하겠습니까?
단체활동에서 의견 충돌이 일어날 경우 어떻게 해결하겠습니까?
대인관계에서 가장 중요하게 생가가하는 건 뭔가요?
오늘 면접 보는 지원자들 중 누가 제일 먼저 말을 걸었습니까?
관심사/ 가치관
봉사 활동을 특별히 많이 했는데, 기업의 사회 환원 활동에 대한 본인의 생각은 어떻습니까?
가장 존경하는 인물은 누구입니까?
가장 인상 깊게 본 영화가 뭐고 이유는 뭔가요?
가장 존경하는 인물로 부모님을 언급했는데, 이유가 있나요?
매일 아침 신물을 읽는다고 했는데, 오늘 아침 신문의 톱기사는 무엇입니까?
한 달에 책을 몇권 정도 읽나요?
본인만의 스트레스 해소법이 있나요?
정보를 수집할 때 효율적인 자신만의 방안이 있나요?
공익과 사익 중 무엇을 더 추구해야 한다고 생각합니까?
평소에 결정할 때 과감하게 하는 편입니까? 아니면 신중하게 하는 편입니까?
본인의 가치관에 대해 말해보고 그 가치관이 우리 회사에선 어떻게 발휘 될 것인지 설명해보세요.
만약 일할 때 로비나 뒷거래가 일어난다면 어떻게 해결할 건 가요?
돌발/ 창의성
당신이 면접관이라면 어떤 걸 중심으로 평가하겠습니까?
한 달을 시한부로 살 수 있고, 5000만원의 돈이 주어진다면 어떻게 사용할 건가요?
빨간 벽돌을 건축자재 외에 사용할 수 있는 용도를 최대한 많이 말해보세요.
읽지않은 이메일이 2000통 있습니다. 이중 300통만 답변이 가능하다면 어떤 것 부터 하겠습니까?
전국에 치킨집이 몇개 있을까요?
서울 시내의 중국집 전체의 하루 판매량을 논리적인 근거를 제시하여 정산해보세요.
아이들을 웃게하는 방법이 뭘까요?
자신이 얼마짜리 사람이라고 생각하나요?
압박질문
다른 회사도 지원했습니까?
다른 회사는 전형이 어디까지 진행되었습니까?
다른 회사에도 합격하면 어디에 입사할 건가요?
열심히 일하겠다고 밝혔는데, 구체적으로 어떻게 열심히 할건가요?
우리 히사에 지원했다가 떨어진 이력이 있는데, 그 때는 왜 떨어진거 같나요? 다시 지원한 이유가 있나요?
** 아래 글은 개인의 조사를 바탕으로 주관적으로 작성되었습니다. 잘못된 부분은 댓글로 남겨주시면 수정하겠습니다.
DevOps ?
최초 데브옵스의 개념은 2009년 O'Reilly에서 주회한 Velocity 컨퍼런스에서 등장했다고 한다.
당시 루디코프 사의 엔지니어 2명이 '10+ Deploys per Day : Dev and Ops Cooperation at Flickr' 라는 이름으로 프레젠테이션했다.
이 발표에선 전통적인 조직의 개발과 운용 부서는 서로 대립되는 구도에 놓인다고 했다.
가장 큰 이유는 각 부서의 입장 차이인데 개발 부서는 변화를 원하지만 운용 부서에서는 서비스의 안정을 위해 시스템의 큰 변화를 원치 않기 때문이다. 하지만 이런 대립 관계가 심화되면 아래의 과정을 거쳐 음의 무한반복 사이클(악순환)이 생기 때문에 조직에 많은 문제가 발생한다.
1. 운용 부서에서는 안정성을 이유로 개발 부서의 변화 의견을 거부한다.
2. 개발 부서는 임의로 내용을 변경하고 해당 내용을 운용 부서에 전달하지 않는다.
3. 운영 부서가 인지하지 못한 변화로 서비스에 예기치 못한 사고가 발생한다.
4. 위 과정이 반복되면 갈등이 더 심화되며, 심화된 갈등으로 더 깊의 음의 무한 반복 상태에 놓인다.
이런 문제를 해결하기 위해 발표에선 몇가지 도구와 문화, 그리고 변화에 대응하기 위한 지표를 제시하였지만 초반엔 기존의 기업 문화가 남아있어 많은 비난을 받았었다. 하지만 변화의 흐름이 빠른 현재는 DevOps 적용에 대한 긍정적인 신호들이 많이 보인다.
DevOps는 Development 팀과 Operations 팀 간의 원활하고 지속적인 커뮤니케이션, 협업, 통합, 가시성 및 투명성(Continuous Integration)을 추구한다. 이런 노력들은 추가 개선, 개발, 테스트 및 구축에 대한 지속적인 고객 피드백 루프를 추진하는 원동력이 되며, 필요한 기능의 변경 및 추가 작업을 더 빠르고 지속적으로 배포(Continuous Deployment)할 수 있게 된다.
DevOps 와 Agile 방법론
DevOps 한장 요약
위의 이미지는 위키피디아에서 가져왔다. 개인적으로 DevOps의 위치를 가장 잘 요약한 그림이라고 생각한다.
방법론에 대한 자료를 조사하면서 Agile 방법론에 대한 내용을 많이 볼 수 있었는데 대부분은 DevOps가 Agile의 발전된 버전이라는 예시를 들었다. (정확한 비교는 아니라고 생각하지만 초반에 개념 이해에 도움을 줬다.)
소프트웨어 개발 방법론은 말 그대로 소프트웨어 만드는 방법에 대한 이론이다.
규모가 큰 소프트웨어의 개발을 위해서는 기획 의도와 구성, 절차 등을 미리 작성해둘 필요가 있기 때문에 전통적인 방법론(waterfall, CBD, 객체지향)들이 연구되고 프로젝트에 적용되었다. 하지만 전통적인 방법론들은 절차를 중시하여 설계 되었기 때문에 빠른 변화에 민첩하게 대응하기 어려웠다.
여기서 빠른 변화에 대한 대응을 위해 계약과 절차보다는 고객과의 상호작용과 협력을 더 중시하는 Agile 방법론이 발생하게 된다.
Agile과 DevOps의 지향점은 근본적으로 같지만 각 방법론의 목표와 실천 방식은 차이가 있다.
Agile은 빠른 프로토타입, 반복과 피드백을 통한 지속적인 퀄리티 향상을 추구하며 고객과의 상호작용에 초점을 두는 반면 DevOps는 상호작용을 포함하여 개발팀과 운영팀 간의 긴밀한 협력 관계를 구현할 수 있는 도구(파이프라인)의 구축을 추구한다. 또한 Agile은 각 상황별 장단점이 있는 다양한 방법론을 사용하는 등 여러 케이스를 나누고 각 케이스별 실천법을 다루지만 DevOps는 각 실천법들의 장점을 채택하여 하나의 체계로 녹여낸다는 차이점이 있다.
Agile은 눈에 보이지 않는 형이상학적 개념을 강조한다. DevOps 또한 동등한 개념과 가치를 중요하게 생각하지만, 도구와 프로세스 정규화 등을 통해 눈에 보이는 성과를 만들어 낼 수 있다. (이런 부분들 때문에 DevOps가 Agile의 발전형이라는 말이 나온 것 같다.) 하지만 업무 프로세스를 정규화하고 다양한 도구들을 사용해 환경을 구축한다고 하더라도 결국은 그걸 사용하는 사람들의 적극성과 이해도가 가장 중요하다.
그러므로 DevOps는 개발-운영팀은 물론 조직 내의 공통된 문화로 정착 되어야 하며, DevOps의 파이프라인은 각 부서의 특성과 문화를 고려하여 설계, 구축한 뒤에도 꾸준한 관리와 교육 훈련이 진행되어야 한다.
Why ?
DevOps는 문화이자 방법론이다. 최근의 공고를 보면 DevOps 엔지니어를 구한다는 글도 꽤 자주 보인다.
그런데 위의 엔지니어가 DevOps 방법론을 적용하고 조직에 어떤 문화를만들어 주는 사람이나 역할을 지칭한다면 뭔가 이상하다. Agile 엔지니어 또는 객체지향, CBD 엔지니어라는 말은 들어본 적 없기 때문이다.
DevOps 엔지니어는 왜 필요할까?
당연히 정답은 없겠지만 여러 자료를 찾아보고 고민하면서 내가 내린 결론은 단순했다.
DevOps 자체로도 업무 범위가 넓고, 개발자나 운영자가 기존의 업무와 병행해서 하기 어렵기 때문이다. (팀의 능력이 뛰어나다면 가능은 하겠지만, 기존 팀의 업무에 추가로 적지 않은 양의 업무가 부여된다면 많은 문제가 생길 것 같다.) 또한 파이프 라인이 존재하기 때문에 기존의 방법론들보다는 해야할 일이 명확하고 가시성이 좋다.
DevOps 에서 파이프 라인은 자동화된 프로세스의 세트(CI/CD, 인프라와 툴체인 등)를 의미한다.
이런 파이프 라인은 소프트웨어의 생명 주기의 전체 과정에 관여하게 되는데, 이런 환경을 구성하려면 다양한 도구들을 다뤄야 한다. 또한 그렇게 환경을 만든 이후에도 해당 인프라를 안정적으로 관리, 모니터링하며 지속적인 교육과 홍보를 해야한다.
위 모든 업무를 기존의 업무와 병행하며 하기엔 물리적으로 힘들어보인다.
기존 팀에게 해당 업무를 부여할 경우, 효율을 올리기 위해 하는 업무가 오히려 팀의 발목을 잡는 것이다.
How ?
DevOps를 직접 구현해야 한다면 핵심 과제는 크게 문화와 파이프 라인이라는 2가지 범주로 나눠진다고 생각한다.
문화를 구현하는 방법은 (많은 실천법들이 있긴하지만) 너무 추상적이다. 하지만 이 중 파이프라인을 구현할 도구들은 이미 많이 있다. 아래 이미지는 소프트웨어 생명 주기의 각 단계 별로 해야하는 역할과 그 역할을 수행할 수 있는 툴들을 NetApp 이라는 업체에서 정리한 내용이다. 각 툴들이 하나의 연결 고리를 이루며, 모든 체인이 엮어 유기적으로 작동하면 'DevOps 툴체인'을 이룬다.
DevOps 툴체인
NetApp 페이지 내용 일부
DevOps 팀은 각 도구들을 조직의 환경에 맞게 적절히 활용하여 툴체인을 현실에 구현하고 유지, 관리 해야한다.
또한 이러한 툴들을 개발-운영 부서가 적극적으로 사용할 수 있도록 지속적으로 사용법을 교육, 문서화하고 장기적으로는 이러한 업무 방식을 조직내에 문화화(enculturation) 시켜야한다.
하지만 구체적인 방법들을 여기서 전부 작성하기엔 여백이 부족하다. 문화화를 위한 여러 실천법 (칸반과 스크럼 등) 과 파이프 라인을 구축하기 위한 툴의 사용법 등은 하나씩 공부하면서 앞으로 다른 글들을 통해 다뤄보겠다.
그래프에서 간선들 사이의 가중치와 방향이 있을 때, 한 정점에서 다른 정점들까지의 최단 거리를 구할 수 있는 알고리즘은 다익스트라, 벨만포드, A* 등이 있고, 모든 정점에서 모든 정점의 최단 거리를 구하는 알고리즘에는 플로이드 워셜 알고리즘이 있다.
해당 알고리즘들을 응용하여 최단 거리를 가지는 경로를 구하는 방법도 있지만, 이 글에서는 다익스트라 알고리즘을 활용하여 최단 거리만 구해보겠다.
먼저 우선순위 큐를 사용하지 않는 최초의 다익스트라 알고리즘은 아래 과정과 같고 O(V2) 의 시간 복잡도를 갖는다. (2중 for 문 구조)
시작 노드 결정
현재 노드를 기준으로 각 노드의 최소 비용을 계산
방문 하지 않은 노드 중 최소 비용의 노드를 선택
선택된 노드를 기준으로 거리 비용을 계산하여 더 가까울 경우 갱신
3~4를 반복하여 모든 노드를 방문
여기서 힙(우선순위 큐) 구조를 사용하면 O(log N)의 시간 복잡도로 값을 구할 수 있는데, 모든 간선에 대해 비교를 해야하므로 우선순위 큐로 구현된 다익스트라 알고리즘은 O(E * Log V) 의 시간 복잡도를 가진다.
아래 내용에서는 각 알고리즘의 특징과 방법을 정리하고 C++ 코드로 구현했다. (간선과 가중치 형태 입력, 인접 리스트)
다익스트라(Dijkstra) 알고리즘 - O(N2)
그래프 사이에 가중치가 존재할 경우 경로를 갱신해가며 한 정점에서 다른 정점까지의 하나의 정점을 기준으로 각 노드의 최단 거리를 알 수 있다. 다익스트라 알고리즘은 양의 가중치를 가진 그래프에서 O(N2)의 시간 복잡도를 갖는다.
아래와 같은 그래프가 있을 때 A에서 각 정점까지의 최단거리를 위의 알고리즘을 따라서 계산해보자.
그래프
1. 시작 노드는 A
2. 현재 노드를 기준으로 각 노드의 최소 비용을 계산
최초에 A에서 시작노드를 제외한 각 정점까지의 거리는 INF(무한)로 초기화되어 있기 때문에
A에서 각 정점까지의 최단 거리는 인접한 정점의 거리로 갱신된다.
(1) - 3. 방문 하지 않은 노드 중 최소 비용의 노드를 선택
A에 인접한 노드 중 방문하지 않은 최소 비용의 노드는 E이다.
(1) - 4. 선택된 노드를 기준으로 거리 비용을 계산하여 더 가까울 경우 갱신
E를 기준으로 최소 비용을 계산하면 아래와 같고, 이 때 E를 거쳐 갈 수 있는 경로가 없으므로 갱신하지 않는다.
5. 3~4를 반복하여 모든 노드를 방문
모든 노드를 방문하지 않았으므로 3~4를 반복한다.
(2) - 3. 방문 하지 않은 노드 중 최소 비용의 노드를 선택
E에 인접한 노드 중 방문하지 않은 최소 비용의 노드는 없으므로, A에 인접했던 노드 중 최소 비용의 방문하지 않은 노드인 C 노드를 선택한다.
(2) - 4. 선택된 노드를 기준으로 거리 비용을 계산하여 더 가까울 경우 갱신
C 노드를 지나가는 경로 중 기존의 거리보다 가까운 경우는 D와 F 노드로 가는 경로이다.
해당 값들을 갱신해준다.
(3) - 3. 방문 하지 않은 노드 중 최소 비용의 노드를 선택
C 노드의 인접 노드 중 방문하지 않은 최소 비용 노드는 D이다.
(3) - 4. 선택된 노드를 기준으로 거리 비용을 계산하여 더 가까울 경우 갱신
D 노드를 지나가는 경로 중 기존의 거리보다 가까운 경우는 F 노드로 가는 경로이다.
A-D의 최소 거리인 3과 D-F의 거리인 2를 더하면 5로 기존의 6보다 가깝다.
(4) - 3. 방문 하지 않은 노드 중 최소 비용의 노드를 선택
D 노드의 인접 노드 중 방문하지 않은 최소 비용 노드는 F이다.
(4) -4. 선택된 노드를 기준으로 거리 비용을 계산하여 더 가까울 경우 갱신
F 를 거쳐 B로 가는 비용 8과 E로 가는 비용 11은 기존 거리보다 멀기 때문에 갱신하지 않는다.
(5) -3. 방문 하지 않은 노드 중 최소 비용의 노드를 선택
F 노드의 인접 노드 중 방문하지 않은 최소비용 노드는 B이다.
(5) -4. 선택된 노드를 기준으로 거리 비용을 계산하여 더 가까울 경우 갱신
B 를 거쳐 C 로 가는 경로의 거리 4는 기존 거리보다 멀기 때문에 갱신하지 않는다
6. 탐색 종료
모든 노드와 경로를 방문하였기 때문에 탐색을 종료한다.
A 노드에서 나머지 다른 노드로 가는 과정을 하나의 표로 나타내면 아래의 그림과 같고, 위 그래프에서의 다익스트라 결과는 0 3 2 3 1 5 이다.
다익스트라 과정과 결과
이제 위의 과정을 C++ 코드로 구현 해보자.
#include <iostream>
#include <utility>
#include <vector>
#include <cstring>
using namespace std;
int main() {
int n, m, start, max = 99999999;
int min = max, current;
int u, v, a;
cin >> n >> m;
// 방문 여부 초기화
int* visit = new int[n+1];
memset(visit, 0, sizeof(int) * (n+1));
int* d = new int[n];
for (int i = 0; i < n; i++) {
d[i] = max;
}
// 인접 리스트 형태로 입력
vector<pair<int, int>>* adjlist = new vector<pair<int, int>>[n];
cin >> start;
// 노드의 번호(A:1)를 인덱스로 변경(1->0)
if(start > 0) start--;
d[start] = 0;
// 입력
for (int i = 0; i < m; i++) {
cin >> u >> v >> a;
adjlist[u - 1].push_back({ v - 1, a });
}
// 시작노드의 인접 노드 거리로 갱신
for (auto tmp : adjlist[start]) {
d[tmp.first] = tmp.second;
}
// 시작 노드 방문 처리
visit[start] = 1;
// 다익스트라 시작
for (int i = 0; i < n - 1; i++) {
min = max;
current = 0;
// 현재 최단 거리 중 방문하지 않은 노드의 인덱스와 거리를 찾는다.
for (int j = 0; j < n;j++) {
if (d[j] < min && !visit[j]) {
min = d[j];
current = j;
}
}
// 찾은 노드를 방문 처리
visit[current] = 1;
// 현재 노드의 인접 노드 중 방문하지 않은 노드의 거리를 비교하여 갱신
for (auto cur : adjlist[current]){
if (!visit[cur.first]) {
if (d[current] + cur.second < d[cur.first]) {
d[cur.first] = d[current] + cur.second;
}
}
}
}
// 최종 결과 출력
for (int i = 0; i < n; i++) {
cout << d[i] << " ";
}
cout << "\n";
return 0;
}
우선순위 큐 다익스트라(Dijkstra) 알고리즘 - O(N log N)
위의 코드에서는 거리를 비교하고 갱신하기 전에 방문하지 않은 노드 중 최단 거리인 노드를 확인하여 가장 짧은 거리를 선택하도록 했다. 하지만 같은 내용을 매번 반복하였기 때문에 알고리즘의 시간복잡도가 늘었다.
최초 알고리즘이 나온 이후 이런 부분을 개선한 다익스트라 알고리즘이 공개되었는데, 우선순위 큐의 특성을 활용한 다익스트라 알고리즘이다.
우선 순위 큐는 항상 우선순위가 높거나 낮은 값을 pop한다. (우선순위 큐는 시간복잡도가 삽입/삭제 시 항상 O(log N)인 최소힙과 최대 힙을 이용하여 주로 구현된다고 한다. 우선순위 큐를 직접 구현하고 싶다면 https://hwan001.tistory.com/199 글을 참고하자.)
C++에서는 우선순위 큐를 직접 구현할 필요가 없다.
STL을 통해 해당 자료구조를 제공하기 때문인데, priority_queue 타입을 사용하면된다.
해당 자료형에 대한 내용은 위의 우선순위 큐 글에 남겨두겠다.
코드로 구현해보자.
#include <iostream>
#include <utility>
#include <queue>
#include <vector>
#include <cstring>
using namespace std;
void dijkstra_pq(int start, vector<pair<int, int>>* graph, int *d) {
int _current, _next, _distance, _nextDistance;
d[start] = 0;
priority_queue<pair<int, int>> pq;
pq.push({0, start});
while (!pq.empty()) {
_current = pq.top().second;
_distance = -pq.top().first;
pq.pop();
if (d[_current] < _distance)
continue;
for (int i = 0; i < graph[_current].size(); i++) {
_next = graph[_current][i].second;
_nextDistance = _distance + graph[_current][i].first;
if (_nextDistance < d[_next]) {
d[_next] = _nextDistance;
pq.push({-_nextDistance, _next});
}
}
}
}
int main() {
int n, m, start, max = 999999999;
int u, v, a;
cin >> n >> m;
int* d = new int[n];
for (int i = 0; i < n; i++) {
d[i] = max;
}
vector<pair<int, int>>* adjlist = new vector<pair<int, int>>[n];
cin >> start;
for (int i = 0; i < m; i++) {
cin >> u >> v >> a;
adjlist[u - 1].push_back({ a, v - 1 });
}
dijkstra_pq(start-1, adjlist, d);
for (int i = 0; i < n; i++) {
if (d[i] == max) {
cout << "INF ";
}
else {
cout << d[i] << " ";
}
}
cout << "\n";
return 0;
}